機械学習エンジニアってなんだろう?
お久しぶりです!EMです^^
2月も半分が過ぎてしまいました。早いですね~。
私が住んでいるトロント市は現在ロックダウンしており
その上今週から非常事態宣言も発表されて、ますますコロナの厳戒態勢が
強まっていました。
ただ、周辺の地域はロックダウンが解除されつつあるのと
ワクチンも少しずつ普及しているみたいなので
どんどん状況が改善されるといいですね。
さてさっそくですが本題です!
今回は他の人がどの様にして、機械学習エンジニアとして
実際どんな事をしているのか、海外の記事を参考にしながら
読み解いていきたいと思います。
国によってはエンジニアの仕事も様々だと思うので、日本やそれぞれの会社によっては
全く同じことがいえるかどうかは分かりませんが、参考程度にぜひ読んでみて下さい!
今回はこちらの記事を参考にしているので、英語の勉強がてら
併せて見てみて下さいね。(本記事は下の記事の一部を取り上げています。)
How to become a Machine Learning Engineer in 2020 | by Jeffrey Luppes | Towards Data Science
さっそく悲報ですが、私がたまにカナダの求人を眺めていても
あまりMachine learning engineerとして、機械学習エンジニアの超エキスパートを
求めている企業はあまりない、という印象があります。
多いのはdata scientistやsoftware engineerの求人で高ポイントになる1つのスキルとして
ML(機械学習)が使えれば尚好し!みたいな位置づけをされている事が多いです。
そんな中で、下の表は一般的なMLエンジニアが行っている一連の流れです。
生のデータから実際に使えるデータとして加工される内容を
ざっくり表しています。
真ん中の小さな黒い四角が見えますか?
四角の大きさが、全体の流れの割合も表しているのでしょう。
MLエンジニアは毎日毎時間、MLのコードを書いて、モデルやアルゴリズムを試行錯誤している訳ではなさそうです。実際は仕事の5~10%の割合みたいですね。
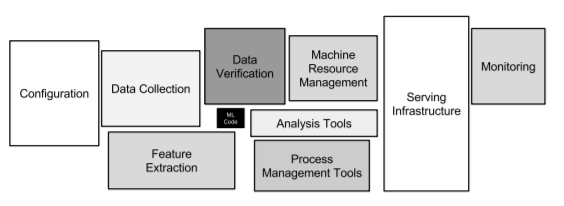
“Hidden Technical Debt in Machine Learning Systems” by Scully et al. (2015)
さらに、MLエンジニアとは一体どんな事をしているのか?という定義がこちらです
…A person called a machine learning engineer asserts that all production tasks are working properly in terms of actual execution and scheduling, abuses machine learning libraries to their extremes, often adding new functionalities. (They) ensure that data science code is maintainable, scalable and debuggable, automating and abstracting away different repeatable routines that are present in most machine learning tasks. They bring the best software development practices to the data science team and help them speed up their work…
— Tomasz Dudek in “But what is this “machine learning engineer” actually doing?”
google先生の直訳は下記です。
…機械学習エンジニアと呼ばれる人は、すべての本番タスクが実際の実行とスケジューリングに関して適切に機能していると主張し、機械学習ライブラリを極限まで悪用し、多くの場合、新しい機能を追加します。 (彼らは)データサイエンスコードが保守可能、スケーラブル、デバッグ可能であることを保証し、ほとんどの機械学習タスクに存在するさまざまな反復可能なルーチンを自動化して抽象化します。 彼らは最高のソフトウェア開発プラクティスをデータサイエンスチームにもたらし、彼らの仕事をスピードアップするのを助けます…
要は、MLエンジニアはデータサイエンティスト達のモデルを改善して
より良い精度かつスピードアップを図っていく事が、一般的な位置づけの様です。
先日のThe Social Dilemmaの映画の内容でもありましたが
特にビックデータを扱っている大企業は、ディープラーニングや
リコメンダ―システムを駆使していて、顧客の興味をひいているので
MLエンジニアがデータサイエンティストや企業そのものを根底からサポートしている
と言っても過言ではないような気がします。
今後はますますビックデータを扱いたい企業や団体が出てくると思うので
MLエンジニアの需要も増えていきそうですね。
ちなみに、今後MLエンジニアやデータサイエンスを通じて
転職やキャリアップを考えている方にぜひ検討してみてほしいのがこちらです!
↓↓データミックス

かなり口コミもよさげで、講師陣も現役バリバリの人ばかりみたいです。
気になる方は、このデータミックスが提供しているコースの
メリットデメリット等も解説してみたので、併せてこの記事も参考にしてみてください^^
↓↓
machinelearningforbeginner.hatenablog.com
それでは今回はここまでです。
最後まで読んで頂きありがとうございました!
分類アルゴリズム~決定木~おまけ編
こんにちは!EMです^^
今回は分類アルゴリズム関連の知って得する知識を
さらっと学んでいこうと思っています!
分類アルゴリズムのヒント(Classification Tips)
高いカーディナリティ(high cardinality)
機械学習の世界では、「カーディナリティ」とは、特徴(feature)が想定できる
ありうる限りの値の数を指します。
たとえば、変数「US State」は、50通りの可能性を持つ値の変数です。
それを踏まえた上で、列のカーディナリティが高い場合
その列にはユニークな値が高い状態にあると言えます。
例えばカーディナリティの高い「列50」のデータを使用すると
情報が多すぎて一般化できない可能性が高く
トレーニングデータを過学習する可能性が高くなります。
高いカーディナリティへの対応方法
高いカーディナリティの一例として、郵便番号があげられます。
今回は郵便番号に焦点を当てた対応法としては
・ドメイン知識を使用して、これらの特徴を地域などのカーディナリティが
低いグループとして分けていきます。
(米国北東部などは、人気がある地域なのか?低いカーディナリみたいです)
*ドメイン知識とは、特定の分野の知識や理解、トレンドなどの情報です。
・最も頻度の高い値(トップ10など)をピックアップし
残りを「その他」としてグループ化します。
アンバランスなクラス(Unbalanced classes)
ターゲット変数の分布がかなり偏っている場合(たとえば、1が異常に少なく、0が多い場合)
モデルのパフォーマンスを検証するために使用される一般的なメトリックが破棄されます。
たとえば、1クラスの発生率が1%しかない場合、全部0だと呼ぶことが出来て
かつ99%の確率で正しいと言えるでしょう。
ただこれは、精度は高いですが、まったく役に立たないモデルです。
アンバランスなクラスを対処する方法の1つとして
発生率の低いクラスのオーバーサンプリング(重複の作成など)と
発生率の高いクラスのアンダーサンプリングを行って、発生率をバランスに近づけることです。
*オーバーサンプリング/アンダーサンプリング…
データ分析の中で、データセットのクラス分布を調整する為のテクニックの事
今回は分類アルゴリズムのおまけ編という事で
豆知識を盛り込んでみました。
ちなみに、もしもっと知りたい!という方は、ぜひコメントを残して頂くか
プロのエンジニアの方に効率的に学んでいくのをオススメしています。
↓↓データ分析コースなどなど↓↓

それでは最後まで読んでいただき、ありがとうございました^^
【機械学習・データ分析を勉強している方必見】オススメの本2選!
こんにちは!EMです^^
今回は私が最近読んだ機械学習系の本を紹介していきたいと思います!
サイトで検索する事も、勉強にはかかせませんが
やはり本を読むと、全体的の流れがつかみやすいのと
情報の中身がかなり安定しているので、信頼できる情報が多いです。
サイトの中には最新の情報もあれば、古い情報もありますからね。
ということで、私の好みで選んだ
めっちゃ分かりやすくて為になると思った本を2冊紹介します!!
まずはこちら↓↓
リンク
これは、もっと早く出会いたかったと思った本です。
この中にはお客様の声や、ECサイトの分析をするなら、小売店の分析をするなら、、
とそれぞれ起こりうる問題や解決策を、実務目線でまとめてくれています。
とそれぞれ起こりうる問題や解決策を、実務目線でまとめてくれています。
個人的な経験からですが、機械学習やデータサイエンスの基礎をおさえた
本や情報はたくさん見つかるのですが、独学学習者からすると
実際の現場でどのような依頼を受けるのかは未知なんですよね。
実際の現場でどのような依頼を受けるのかは未知なんですよね。
(もちろん現場によってそれぞれだと思いますが…)
また、私が小売店で勤務していることもあり、自分の業務と
照らし合わせて使える内容ばかりだったので、とても重宝しています。
照らし合わせて使える内容ばかりだったので、とても重宝しています。
という事で、ざっくりでも基礎を学んだ方には
データサイエンティストがこんな事をしているというイメージを掴むためにも
ぜひ読んでみてほしい一冊です!
データサイエンティストがこんな事をしているというイメージを掴むためにも
ぜひ読んでみてほしい一冊です!
さて、次の本にいきましょう。
リンク
さて、この本にはデータ分析に必要なすべてを網羅しているといっても
過言ではありません!(個人的な意見です)
過言ではありません!(個人的な意見です)
特に文系の人に苦手意識があるのではなかろう、確率や統計についても
きっちりまとめてくれています!
きっちりまとめてくれています!
もちろん初めて見る専門用語ばかり、、という人には
一度で理解するのはむずかしいかもしれません。
一度で理解するのはむずかしいかもしれません。
ただ図や公式なども含めて解説してくれていて
「この内容を理解したいから、この単語を調べてみよう!」という
何が分からないかを明らかにしてくれる、基礎固めのとっかかりが出来る本かな
と思っています。
「この内容を理解したいから、この単語を調べてみよう!」という
何が分からないかを明らかにしてくれる、基礎固めのとっかかりが出来る本かな
と思っています。
私は1冊目の本から疑問があれば、2冊目の本で調べて
分からないところを時間をかけても理解していく、という勉強をしています。
正直にいうと、私はkindleの電子書籍を購入したのですが
パソコン版でみると、メモやハイライトを残したりできる機能が使えず
やはり紙の方が付箋とか使えて使いやすいなぁと感じました。
パソコン版でみると、メモやハイライトを残したりできる機能が使えず
やはり紙の方が付箋とか使えて使いやすいなぁと感じました。
ただ移動が多い方はやはり持ち運びはしやすいので
電車などの通勤時間に見て勉強はしやすいです。
電車などの通勤時間に見て勉強はしやすいです。
まぁ何事も長所短所はありますからね。
という事で、今回はいちおしの書籍を紹介させて頂きました^^
最後まで読んで頂きありがとうございました!
分類アルゴリズム~決定木④アンサンブル手法~
こんにちは!EMです^^
今回も引き続き決定木シリーズを解説していきます!
メインのテーマはアンサンブル手法です!
アンサンブル手法(Ensemble methods)
ランダムフォレスト:
たくさんの決定木を並行して構築し、多数決を使用して
出力を1つのモデルにかしこく結合します。
合計データのサブセット(サンプリング)が各決定木に使用され
最後に集計(バギング:bagging)が行われてすべてがまとめられます。
ブーストツリー:
たくさんの決定木を連続して構築します。
後続のモデルは、前のモデルのエラーを元に構築されます。
この構成では、前のモデルで捉えられなかった効果に追加のモデルが適合します。
そして最後に、異なるモデルが一緒に追加されて最終的な結果が得る事が出来ます。
ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
random_forest_model = RandomForestClassifier(n_estimators=50, max_depth=5)
random_forest_model.fit(X_trn[features_to_include], Y_trn)
print('accuracy on training data',random_forest_model
.score(X_trn[features_to_include], Y_trn))
print('accuracy on test data',random_forest_model
.score(X_tst[features_to_include], Y_tst))
【output】
accuracy on training data 0.8004733727810651
accuracy on test data 0.8030518097941802
【2つの特徴に絞った場合】
random_forest_model_2feat = RandomForestClassifier(n_estimators=50, max_depth=5,)
random_forest_model_2feat.fit(X_trn[two_features], Y_trn)
print('accuracy on training data',random_forest_model_2feat
.score(X_trn[two_features], Y_trn))
.score(X_trn[two_features], Y_trn))
print('accuracy on test data',random_forest_model_2feat
.score(X_tst[two_features], Y_tst))
.score(X_tst[two_features], Y_tst))
【output】
accuracy on training data 0.7988165680473372
accuracy on test data 0.7934705464868701
PlotBoundaries(random_forest_model_2feat, X_tst[two_features].values,Y_tst)

木を基にした機械学習の利点として、機能の重要度のランク付けが出来る事にあります。
これを利用する事で、モデルの解釈の可能性に非常に役に立ちます。
df_feat_importances = pd.DataFrame(list(zip(features_to_include,
random_forest_model.feature_importances_)),
columns=['Feature','Importance'])
df_feat_importances.sort_values(by='Importance', inplace=True)
plt.figure(figsize=[6,8])
plt.barh(df_feat_importances['Feature'],df_feat_importances['Importance'])

勾配ブースト木(Gradient Boosted Trees)
※ここでは出力結果を割愛しています。ぜひ一度どんな結果が出るか試してみてください^^
from sklearn.ensemble import GradientBoostingClassifier
gbm_model = GradientBoostingClassifier(n_estimators=50, max_depth=5,
min_samples_leaf=100)
gbm_model.fit(X_trn[features_to_include], Y_trn)
print('accuracy on training data',gbm_model.score(X_trn[features_to_include], Y_trn))
print('accuracy on test data',gbm_model.score(X_tst[features_to_include], Y_tst))
gbm_model_2feat = GradientBoostingClassifier(n_estimators=50, max_depth=5,
min_samples_leaf=100)
gbm_model_2feat.fit(X_trn[two_features], Y_trn)
print('accuracy on training data',gbm_model_2feat.score(X_trn[two_features], Y_trn))
print('accuracy on test data',gbm_model_2feat.score(X_tst[two_features], Y_tst))
PlotBoundaries(gbm_model_2feat, X_tst[two_features].values,Y_tst)
もう一度、機能の重要度を見てみましょう。
df_feat_importances_gbm = pd.DataFrame(list(zip(features_to_include,gbm_model.
feature_importances_)), columns=['Feature','Importance'])
df_feat_importances_gbm.sort_values(by='Importance', inplace=True)
plt.figure(figsize=[6,8])
plt.barh(df_feat_importances_gbm['Feature'],df_feat_importances_gbm['Importance'])
いかがだったでしょうか?
私自身のデータを当てはめた時は、過学習をする事もあり
色々と値を調整しながら当てはめていました。
もしもっと知りたい!という方は、ぜひコメントを残して頂くか
プロのエンジニアの方に効率的に学んでいくのをオススメしています。
↓↓データ分析コースなどなど↓↓
ぜひご検討ください^^
最後まで読んで頂きありがとうございました!
分類アルゴリズム~決定木の視覚化~
こんにちは!EMです^^
今回も引き続き、決定木の特に視覚化について学んでいきたいと思います。
決定木の視覚化(visualizing trees)
構築した決定木を視覚化していきましょう。
その為に、プログラムを含む2つの新しいパッケージをインストールしていきます。
1.オペレーティングシステムにGraphvizをダウンロードします
https://graphviz.gitlab.io/download/
2.Anaconaプロンプトから、conda install graphvizを実行します
3.conda install pydotplusを実行します
from sklearn.externals.six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
フィットモデル(DT_model)を使い、次のスクリプトを実行して木を視覚化できます。
dot_data = StringIO()
export_graphviz(DT_model_2feat, out_file=dot_data, feature_names=two_features,
class_names=['no','yes'],rounded=True, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())

これが英語なので少し分かりにくいですが、決定木がどのように
派生しているのかというのが視覚的にイメージができやすいかと思います。
また正則化する時にも、どの程度の大きさの木を構築したいなどの
ボリューム感を掴むには、こういった方法で確認するのも一つの方法ですね。
またもし本気で今勉強している、したいという方は
ぜひプロのお話を聞くのもおすすめしています。
私のブログでも今後幅広く、内容を解説していきたいと思っていますが
本気で勉強したいという人を応援したいので、ぜひ効率の良い方法もご検討ください。
↓↓データ分析コースなどなど↓↓
それでは今回は短いですが、ここまでにします。
また次回もお楽しみに~^^
分類アルゴリズム~決定木②~
こんにちは!EMです^^
今回も引き続き、決定木について解説していきたいと思います。
決定木①では決定木が過学習しやすいというお話をしました。
では過学習してしまった時、どのように対処していくのかという事を
みていきましょう。
正則化(Regularization)
過学習をコントロールする方法として、事前剪定(pre-pruning)
と呼ばれる手法があります。
決定木は字のごとく木に例えられているので、木の枝が長くなる前に
刈ってしまうというイメージですね。
もしくはポスト剪定(post-pruning)といって、モデルを適合する間に
決定木の長さを調整をしていう方法もよく使われます。
これは一度モデルを適合した後に、決定木の長い枝を切っていくものなのですが
残念ながらsklearnの中には実装されていません。
ここでは2つの事前剪定手法に注目していきたいと思います。
1.max_depthを使用して、枝(ノード)の数を制限します。
これにより、木全体の複雑さが制限されて、個々のデータポイントごとに
必要以上に過学習を招く事を防ぎます。
2.min_samples_leafを使用して、各エリアがカバーする必要のある
データポイントの数に下限の値を設定します。
これにより、決定木はデータ量の多い領域に適合し
少ないデータポイントごとに特定の領域が作られるのを防ぎます。
どちらの手法も比較的うまく機能する事が多いです。
詳細については、こちらのサイトも参照してみてください。
http://scikit-learn.org/stable/modules/tree.html#tips-on-practical-use
DT_model_2feat = tree.DecisionTreeClassifier(max_depth=5, min_samples_leaf=50)
DT_model_2feat.fit(df[two_features], df['Churn'])
PlotBoundaries(DT_model_2feat, X_tst[two_features].values,Y_tst)

DT_model_2feat = tree.DecisionTreeClassifier(max_depth=3, min_samples_leaf=50)
DT_model_2feat.fit(X_trn[two_features], Y_trn)
print('accuracy on training data',DT_model_2feat.score(X_trn[two_features], Y_trn))
print('accuracy on test data',DT_model_2feat.score(X_tst[two_features], Y_tst))
【output】
accuracy on training data 0.7815384615384615
accuracy on test data 0.7867281760113556
Notice how much simpler our boundaries are, and how there was minimal dropoff in accuracy on unseen data
前回の出力結果に比べると、プロット図がよりシンプルになったこと
またテストデータの精度の低下が最小限になり、過学習を解消できたという点に
お気づきになりましたか?
次回は決定木の違った形の視覚化について、解説していきたいと思います^^
またもし本気で今勉強している、したいという方は
ぜひプロのお話を聞くのもおすすめしています。
私のブログでも今後幅広く、内容を解説していきたいと思っていますが
本気で勉強したいという人を応援したいので、ぜひ効率の良い方法もご検討ください。
↓↓データ分析コースなどなど↓↓
最後まで読んで頂きありがとうございました^^
分類アルゴリズム~決定木①~
こんにちは!EMです^^
さっそく今日も分類アルゴリズムシリーズをはじめていきたいと思います。
今日のテーマは「決定木」です!
決定木(Decision Trees)
決定木はイメージしやすいかもしれません。
例えば、10個ほどの質問をして、答えにたどり着くタイプの質問がよく
身近に目にするかと思います。
例えば、回答者は人や物や場所などについて考え、yesまたはnoで答えていきます。
そしてその導かれる答えによって、最終的な回答を予想していきます。
問題を進めていくほど、その回答によって考えられうる解決策を
狭めていく事ができます。
例をいうと「これは動物ですか?」という質問に「はい」と答え
「4本の足がありますか?」の答えが「いいえ」だった場合。
これは明らかに豚、羊、牛、犬などの4足歩行の動物は削除する事が出来ますよね。
この様に、最終的にはうまく答えにたどり着くという流れです。

決定木の木はノード(◇の結び目の部分)で構成され
一番上のノードをルートノード(根っこのノード)と言います。
各ノードは属性のテストを表します。
例えば、「色は『赤』」や「重量は『10kg未満』ですか?」などの質問が
各ノードに入ります。
さらに決定木は、階層モデルの例です。
木がもつ各ノードは、情報を蓄積しており、上からの情報を下に流しています。
一番下の先のないノードの事をリーフノード(木の葉っぱのイメージ)と言います。
リーフノードにたどり着くと、私たちは決定を下したり、結果を得る事が出来ます。
最終的にたどり着いたリーフノードは、その中から一番可能性の高い決定・結果を
表しています。
一般的に、決定木は元の特徴(feature)タイプに影響されません。
継続的な特徴である場合、自由に値を分割できます。
もし独立変数が連続的な特徴値 Xi を持っている場合、分割は値 V で行うことができ
Xi≤V が左の枝になり、すべての値Xi≥Vが右側の枝になります。
分離した特徴には、クラス値で分割できます。
treeパッケージを使用して、決定木を構築してみましょう。
from sklearn import tree
#fitting the DT
DT_model = tree.DecisionTreeClassifier()
DT_model.fit(df[features_to_include], df['Churn'])
DT_model.score(df[features_to_include], df['Churn'])
【output】
0.9974442709072838
DT_model_2feat = tree.DecisionTreeClassifier()
DT_model_2feat.fit(df[two_features], df['Churn'])
PlotBoundaries(DT_model_2feat, df[two_features].values, df['Churn'])

2つの特徴の境界プロット(上の図)から見ての通り、決定木は過学習をする傾向があります。
ここでも、私たちが作ったデータと同じもので仮説を検証するべきではないので
テスト/トレーニングデータを使用してみましょう。
DT_model = tree.DecisionTreeClassifier()
DT_model.fit(X_trn[features_to_include], Y_trn)
print('accuracy on training data',DT_model.score(X_trn[features_to_include], Y_trn))
print('accuracy on test data',DT_model.score(X_tst[features_to_include], Y_tst))
【output】
accuracy on training data 0.9978698224852071
accuracy on test data 0.7331440738112136
目に見えないデータ(テストデータ)を使用すると
精度が一気に低くなった事に気づきましたでしょうか。
精度が一気に低くなった事に気づきましたでしょうか。
これは先程の通り、トレーニングデータ上で過学習をしている可能性が高いというサインです。
次回では正則化(regularization)を通じて、過学習をしてしまった際に
どのように決定木を改善していくのかを見ていこうと思います!
どのように決定木を改善していくのかを見ていこうと思います!
もしブログでは情報が足りない、、という方は
ぜひリクエストやコメントをお待ちしております。
また本格的に学びたい!という方は、ぜひプロにしっかり学ぶというのも
1番効率がいいのは間違いありません。
時間を無駄にしたくないという方は、ぜひ無料体験等で一度
どのように学べるのか試してみてくださいね^^
それでは次回もお楽しみに~!!