Kmeansに関する豆知識①
こんにちは!EMです^^
最近トロントは晴れの日が多くなって、一歩一歩春に近づいています!
やっぱり暖かいと気分も晴れますね♪
それではさっそく、前回からのKMeansシリーズの続きとして
より深くKMeansを考察していく豆知識的な内容を学習していこうと思っています!
前回では、このような内容を話しておりました↓
machinelearningforbeginner.hatenablog.com
その続きの話を今回付け加えようと思います。
適合性を評価する方法
前回の内容の最後の適合は、かなりセンターがずれていて不自然でした。
KMeansモデルを適合する場合、実は裏で計算式が働いています。
各ポイントとそれに割り当てられたクラスター中心との間の
二乗距離の合計を最小化する狙いがあるのです。
公式をいうと、d個の特徴があり、xがデータポイントで
xは最も近いセンターである場合、xをクラスcに割り当てる事ができます。
そしてxとc、2つの間の距離は次のようになります。

その場合、適合の合計スコアは次の合計になります。

x 'は全てのデータポイント
c'はそれに割り当てられた(または1番近い)クラスターのセンターの事です。
目標は、この距離を最小化することです。
ただ、実際には距離を最小化するセンターを見つけることは非常に難しいです。
それに伴い、いくつかの良さげな研究アプローチがあるので見てみましょう。
フィットの実際の距離スコアはinertia_変数に格納され
次のように慣性値を取得できます。
※慣性…物体が常に現在の運動状態を保とうとする性質のこと
print('The fit score (inertia) is: %3.3f' % k_means_model.inertia_)
【outfit】
The fit score (inertia) is: 28.043
Data Scale
KMeansは距離ベースのモデルです。
その為、データの規模が大きな影響を与える可能性があります。
2点間の距離は次のとおりです。

私たちの機能が大きく異なった規模の場合、いくつかの機能の影響は取り除かれます。 その為、KMeansに渡す前にデータをスケーリングすることはよくあります。
Kを選ぶ方法(How to Pick K)
この章では、理想的なクラスターの数を見つける方法について説明します。
適切な数は非常に主観的に決まることが多いです。
いくつかのパターンを見てみましょう。
- カテゴリー従属変数があり、基礎となるクラスの数がわかるとしましょう。
この場合、Kを適切に設定できます。
例えば、がんに関するデータセットがある場合、2つのクラスである事が
わかっているため、2つのクラスターに適合させることができます。 - データを所定の数のクラスに分割していきたいと思います。
仮に小売のデータが手元にあり、分割したい場合は
顧客を事前に決定された数のタイプに分割し、この数をKに使用できます。 - 慣性値を使用して、セクションをガイドする事ができます。
次の3つのクラスターデータを試してみましょう。
points_per_class = 20
mean = [5,5]
cov = [[1,0],[0,1]]
x_one = np.random.multivariate_normal(mean, cov, (points_per_class))
mean = [-5,-5]
cov = [[1,0],[0,1]]
x_two = np.random.multivariate_normal(mean, cov, (points_per_class))
mean = [4,-2.5]
cov = [[0.25,0],[0,0.25]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class))
X = np.concatenate((x_one,x_two,x_three,x_four),axis=0)
そして、慣性値をプロットします。(これは少し時間がかかります...)
k_range = np.arange(1,20)
inertia_list = []
for k in k_range :
#Specify the model
k_means_model = KMeans(n_clusters = k)
k_means_model.fit(X)
inertia_list.append(k_means_model.inertia_)
plt.scatter(k_range,inertia_list)
plt.show()

この表では、すぐに点が急降下し、横ばいになりました。
最初のいくつかのポイントに焦点を当てると…
plt.scatter(np.arange(7),inertia_list[0:7])

3~4番目のドットの後で、値がかなり横ばいになっていると分かります。
これは、新しい重心が慣性をそれほど減少させていないことを意味します。
その為、クラスの理想的な数が3~4つであるといえでしょう。
これはあまり科学的ではありませんが、的を得た予測になる可能性があります。
どのように線引きをするのか決めるのは、難しい作業です。
その為、さらなるデータの判断材料や調査を行う事が重要になるでしょう。
長くなりそうなので、今回はここまでにします!
次回もKmeansに関する豆知識を引き続き解説していきたいと思いますが
もし効率的にプロから学びたい!という方は、専門の学校やレッスンを受ける事を
おススメしています^^
↓↓

これは、実践のビジネスの場でデータを使えるように指導してくれる、社会人の為の講座です!
ぜひサイトや無料説明会等で情報を見てみてくださいね^^
また詳しくは簡単にメリットデメリット等もまとめているので
よかったら下の記事も参考にしてください^^
よかったら下の記事も参考にしてください^^
machinelearningforbeginner.hatenablog.com
最後まで読んで頂き、ありがとうございました!
KMeansで何ができるの?
こんにちは!EMです^^
だんだん春も近づいてきましたね~!
こちらでは雪も解けてきて、気温もプラスの日が続いてポカポカです!
それでは今日もさっそくKMeansについて学んでいきましょう!
KMeansってどんな役割なのか?
前回の例では、KMeansを使ってうまく4つのクラスターを色で分ける事ができました。
ただ、もっと複雑なデータを扱ったときにも、KMeansを使って
客観的なグループ分けが出来るのでしょうか?
KMeansをもう少し掘り下げて理解していきましょう。
このモデルは、K(n_clusters)の特別な点をデータに適合させています。
これらの点は、それぞれのグループに対してラベルをつけていきます。
この点は「センター」と呼ばれ、それぞれがデータのクラスターの真ん中に
配置されます。
最適なセンターを見つけるアルゴリズムの中身は、めちゃくちゃ複雑です。
より詳細を知りたい方は、こちらのURLを参考にしてください。
https://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm
データポイントXのラベルを予測するときは、1番近い中心と同じラベルに
割り当てます。
前回のデータでKMeansモデルを再実行した場合、今回は中心をプロットしました。
points_per_class = 100
mean = [5,5]
cov = [[1,0],[0,1]]
x_one = np.random.multivariate_normal(mean, cov, (points_per_class))
mean = [-5,-5]
cov = [[1,0],[0,1]]
x_two = np.random.multivariate_normal(mean, cov, (points_per_class))
mean = [4,-2.5]
cov = [[0.25,0],[0,0.25]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class))
mean = [-6,2.5]
cov = [[0.25,0],[0,0.25]]
x_four = np.random.multivariate_normal(mean, cov, (points_per_class))
X = np.concatenate((x_one,x_two,x_three,x_four),axis=0)
#Specify the model
k_means_model = KMeans(n_clusters = 4)
k_means_model.fit(X)
#Annotate the data points with the KMeans prediction
Y = k_means_model.predict(X)
#Plot
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolor='k')
#Plot the K centers
plt.scatter(k_means_model.cluster_centers_[:, 0],k_means_model.
cluster_centers_[:, 1], c='red',marker="*",s=200)
plt.show()

各センター(赤い星)がクラスターの中央に割り当てられましたね。
一例として、データラベルの割り当てを変えて、2つのセンターを調整してみましょう。
#Change the center locations (finds a bad fit)
k_means_model.cluster_centers_ = np.array([[ 4.93629851, 4.86487333],\
[-0, -6],\
[ 3.98048973, -2.49005718],\
[-0, -4]])
#Annotate the data points with the KMeans prediction
Y = k_means_model.predict(X)
#Plot
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolor='k')
#Plot the K centers
plt.scatter(k_means_model.cluster_centers_[:, 0],k_means_model.
cluster_centers_[:, 1], c='red',marker="*",s=200)
plt.show()

これで、左上のセンターが近づいたため、左下のクラスターのデータの一部が
新しいクラスター(その真上のクラスターと同じ)に割り当てられます。
今回の図では、上記のクラスタリングはあまりにも不自然ですが
もっと複雑なデータを使って、線引きがきれいに出来ない際に、センターを調整して
様々な角度でグループ分けをする時にとても便利です。
クラスタリングは、ビジネスの場面でもよく使われます!
クラスタリングについては、次回も取り上げようと思いますが
もっと実践に近い内容を学びたい!という方には、めちゃくちゃこのコースが体系的でおススメです。
↓↓
これは、実践のビジネスの場でデータを使えるように指導してくれる、社会人の為の講座です!
ぜひサイトや無料説明会等で情報を見てみてくださいね^^
また詳しくは簡単にメリットデメリット等もまとめているので
よかったら下の記事も参考にしてください^^
よかったら下の記事も参考にしてください^^
最後まで読んで頂きありがとうございました。
クラスタリング② ~KMeansアルゴリズム~
こんにちは!EMです^^
前回の続きになる、クラスタリング関連について
今回も取り上げていきたいと思います!
その中でも、KMeansアルゴリズムについて、勉強していきましょう。
KMeansアルゴリズム(The KMeans algorithm)
教師なしクラスタリングで最初に見るアルゴリズムは
KMeansアルゴリズムです。
アルゴリズム自体は sklearn.clusterの中にあります。
(参考になるドキュメントについては、こちらのURLをご覧ください。
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html)
注目したいパラメーターは、クラスターの数n_clustersです。
デフォルト値は8に設定されています。
KMeansの使い方は、Scikit-Learn内の他のモデルを実行するのと同じです。
モデルを構築し、データに適合させてから、見えないデータを予測します。
データポイントでのモデルの予測はそのポイントが属すると思われるクラスターです。
まずラベルなしの前回の例を使って見てみましょう。
points_per_class = 100
#4つのクラスタリングを作っていきます.
mean = [5,5]
cov = [[1,0],[0,1]]
x_one = np.random.multivariate_normal(mean, cov, (points_per_class))
y_one = np.full*1
y_two = np.full*2
y_three = np.full*3
y_three = np.full*4
y_four = np.full((points_per_class),0)
X = np.concatenate((x_one,x_two,x_three,x_four),axis=0)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
#Plot the data
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()

次にKMeansモデルを適合させましょう。
この場合、4つのクラスタリングに分けるのが妥当だといえるので4つと指定します。
from sklearn.cluster import KMeans
#モデルを特定し、数を指定する
k_means_model = KMeans(n_clusters = 4)
#データにモデルを当てはめる
k_means_model.fit(X);
それでは、データポイントの各々のグループの予測を行います。
Y = k_means_model.predict(X)
#Plot the data:
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()

これはかなり自然に色分けされたクラスタリングでしょう。
ぜひもっと複雑な例でも、実際にクラスタリングが動くがどうか試してみてください。
クラスタリングは、ビジネスの場面でもよく使われます!
もう少しだけクラスタリングについては、次回も取り上げようと思いますが
もっと実践に近い内容を学びたい!という方には、めちゃくちゃこのコースが体系的でおススメです。
↓↓
これは、実践のビジネスの場でデータを使えるように指導してくれる、社会人の為の講座です!
ぜひサイトや無料説明会等で情報を見てみてくださいね^^
また詳しくは簡単にメリットデメリット等もまとめているので
よかったら下の記事も参考にしてください^^
よかったら下の記事も参考にしてください^^
最後まで読んで頂きありがとうございました。
*1:points_per_class),0)
mean = [-5,-5]
cov = [[1,0],[0,1]]
x_two = np.random.multivariate_normal(mean, cov, (points_per_class
*2:points_per_class),0)
mean = [0,0]
cov = [[0.25,0],[0,0.25]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class
*3:points_per_class),1)
mean = [4,-2.5]
cov = [[0.25,0],[0,0.25]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class
*4:points_per_class),0)
mean = [-6,2.5]
cov = [[0.25,0],[0,0.25]]
x_four = np.random.multivariate_normal(mean, cov, (points_per_class
クラスタリング②
こんにちは!EMです^^
今回は前回の続きとして、クラスタリングについて学んでいこうと思います。
この前は、一目でわかる比較的簡単なデータを使ったので
今日は少し複雑なデータを使っていこうと思います。
今日は少し複雑なデータを使っていこうと思います。
#いくつかのデータを作っていきます
mean = [3,3]
cov = [[1,0],[0,1]]
x_one = np.random.multivariate_normal(mean, cov, (points_per_class))
y_one = np.full*1
y_two = np.full*2
y_three = np.full*3
y_four = np.full((points_per_class),0)
X = np.concatenate((x_one,x_two,x_three,x_four),axis=0)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
#Plot
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()

この表はどうやって分ける事ができるでしょうか?
前回の表に比べて、はっきりと線引きするのは難しそうですね。
#例1
y_one = np.full((points_per_class),1)
y_two = np.full((points_per_class),2)
y_three = np.full((points_per_class),3)
y_four = np.full((points_per_class),4)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()
#例2.
y_one = np.full((points_per_class),1)
y_two = np.full((points_per_class),1)
y_three = np.full((points_per_class),2)
y_four = np.full((points_per_class),2)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()
#例3
y_one = np.full((points_per_class),1)
y_two = np.full((points_per_class),3)
y_three = np.full((points_per_class),2)
y_four = np.full((points_per_class),2)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()

上記のそれぞれの色分けは、クラスの数とクラスターの場所に対するありえそうな答えです。
ただ、どれが1番正しいかどうやってわかるのでしょうか?
このような表は、現実世界で多く見られるかと思います。
ビジネスでも、クラスターはよく使われるので、ぜひ使ってみてくださいね。
また今後もクラスターについて解説していこうと思いますが
もしもっと深く勉強したい!という方は、ぜひプロの講師にも力を借りてみてください。
もしもっと深く勉強したい!という方は、ぜひプロの講師にも力を借りてみてください。
これは、実践のビジネスの場でデータを使えるように指導してくれる
社会人の為のおすすめ講座です!
社会人の為のおすすめ講座です!
ぜひサイトや無料説明会等で情報を見てみてくださいね^^
また個人的な意見ですが、簡単にメリットデメリット等もまとめているので
よかったらそちらも参考にしてください^^
よかったらそちらも参考にしてください^^
最後まで読んで頂きありがとうございました。
*1:points_per_class),0)
mean = [1,1]
cov = [[1,0],[0,1]]
x_two = np.random.multivariate_normal(mean, cov, (points_per_class
*2:points_per_class),0)
mean = [-3,-3]
cov = [[1,0],[0,1]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class
*3:points_per_class),0)
mean = [-1,-1]
cov = [[1,0],[0,1]]
x_four = np.random.multivariate_normal(mean, cov, (points_per_class
【社会人の方必読!】未経験からたった6か月でデータサイエンティストになる方法
こんにちは!EMです^^
まもなく2月も終わりますね。
この前までお正月だったのに、もう2か月たった、、、
という方も多いのではないのでしょうか。
という事で、今回超絶変化の激しい2021年に、データサイエンティストの
スキルアップを通じて自分に自信を持ちたい!という方に必見な情報をお伝えします。
他にもこんな方にもぜひ見てもらいたいです。
・今までの社会人経験を活かして、転職や起業へのステップアップへ繋げたい
・データ分析だけでなく、ビジネスの幅広い問題解決をする方法を学びたい
・長い目で見たときに、金銭的な余裕がほしい
(データサイエンティストの平均年収は696万円です!求人ボックス2021年1月6日調べより)
一つでも当てはまれば、ぜひ強くビックデータ時代の先導をきるスキルを
プロの力を借りて勉強する事を強くおススメします。
↓↓今回おススメなのはココ↓↓
データミックスという会社が提供している
「データサイエンティスト育成スクール」というコースがなかなか激熱です。
個人的に私が受講していたbrain stationという似たようなコースを比較すると
・働きながら受講できる
・少人数での指導
・勉強会やイベントへの参加ができる
といったところは同じでした。恐らく他のサービスも似ていると思います。
ただ、データミックスならではで、めっちゃいい!と思ったところがあります。
【メリット】
・ケーススタディの量が多く、実践を想定している
・コース後のフォローアップや、OG/OBのネットワークを通じて転職支援がある
・一人ひとりの強みや弱みを活かした指導をしてくれる
私の学校は、ケーススタディが1件しかなく、あまり時間をかけてもらえなかったので
なかなか実践を意識して勉強するという事ができませんでした。
でもデータミックスは、逆に実践ありきの指導なので、複数のプロジェクト演習が
経験できる且つ、数週間の時間をかけてじっくり勉強する事が出来るようです。
また、現役のデータサイエンティストの講師の指導を受ける事が出来るのは
どの学校も共通かと思いますが、私の場合は1人の先生が指導していたので
絞られた業界の話しか聞くチャンスがありませんでした。
しかし、ここでは複数の講師陣がいるのと、OG/OBのコミュニティがあるというのが
魅力的です。
しかもコース後のフォローアップと転職支援があるというのはめちゃくちゃいいです。
実際お金と時間をかけて、仕事に繋がらなければ、多くの人にとって意味がないと
思いますし、コース卒業後にフォローがなければ、勉強した事を忘れる一方で
自力で学習するにもかなりのモチベーションが必要です。
言い方は悪いですが、周囲の人や成長できる環境に身をおく事ほど大切な事はありません。
さて、ここまでいいことばかりお伝えしてきましたが
ここはデメリットかな、、という内容もあったので、そこも隠さずにお伝えします。
【デメリット】
・フルコース(一括申し込み)は特に受講料の費用が高い
・コースを受講前に試験がある
・学習内容が幅広いので、本気で勉強するという覚悟が必要
こちらが唯一気になった点ですね。
他の学校は1対1の個別指導も売りにしているところもありますが
データミックスのサイトの「受講者の声」から
個々の質問に対しては手厚くサポートしてくれている印象を受けたので
個人的にはグループ学習でも特に問題はないかなと感じました。
2つ目の試験については、「python」と「統計」の知識が問われるそうです。
ただ、うからなくても次の募集でまた挑戦できるみたいですし
不安であれば入門コースやe-learning等のコースもあるようなので
それも併せると十分クリアできるのかなと思います。
個人的には1番ぎょっとしたのが、費用です。
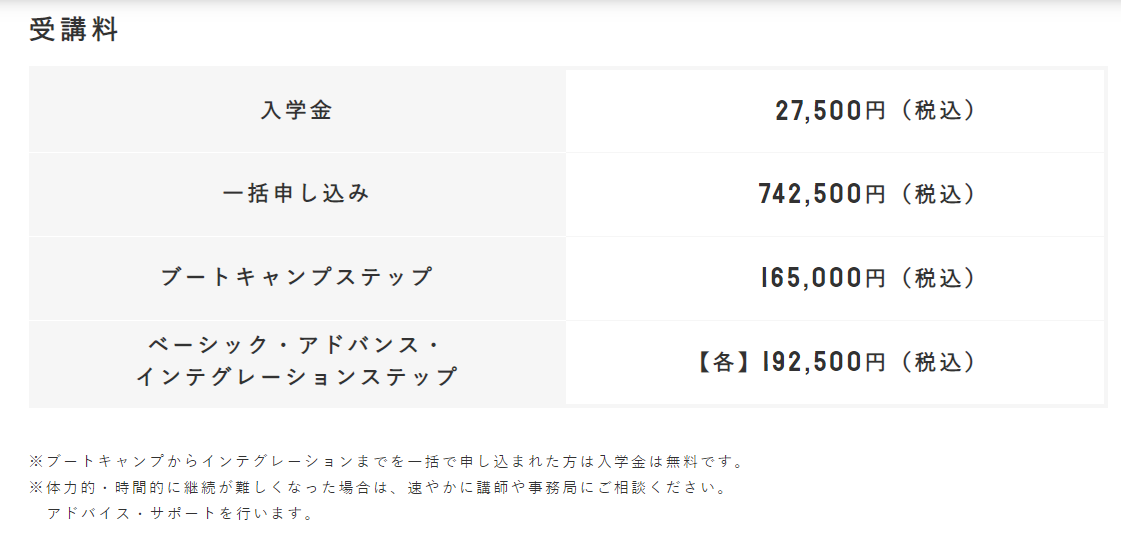
もし、基礎だけ学びたいとか、ピンポイントで学びたいコースがあれば
一括ではなく各々のコースを受講してもいいかもしれません。
ただ、ぜひウェブサイトも見てほしいのですが、全てのコースを受講する際は
742500円かかります!!
6か月+その後のフォローと考えると他の学校とトントンかもしれませんが
それにしても少し慎重になってしまいますよね。
しかし、お金がネックになっている方には朗報があります!!!
一括申し込みを受講した方のみ、教育給付金として
最大70%返還されるという素敵な制度があるんです!!!
もちろん、出席率や成績などの基準はありますが、最大51万円が
キャッシュバックされる可能性があるのです。
これは、データサイエンティストが不足している今だからこそ
厚生労働大臣から用意されているんでしょうね。
データサイエンティストを勉強したいと考えていた人にとっては
仮に全額払っても勉強する価値がある分野ですし
さらに給付金がもらえる可能性があれば
スモールゴールとして、努力のモチベーションもあがるのではないでしょうか。
一括申し込みをした人には さらに、満足保証という制度があり
万が一サービスに満足できなかった場合には返金できるという保証もあります。
※条件があるので、気になる方はサイトから詳細の確認をお願いします。
さて、どうでしたでしょうか?
詳細が気になる方は、オンライン説明会にぜひご参加くださいね^^
↓↓
最後まで読んで頂きありがとうございました!
クラスタリング
こんにちは!EMです^^
今回はクラスタリングについて解説していきます!
クラスタリング
クラスタリングとは、似たようなデータを同じグループに入れるモデルの適合です。
分類(従属カテゴリ変数を含むモデルの適合)は、クラスタリングの形式と
考えることができます。
ここでは、同じ従属変数ラベルを持つすべての点を同じグループに配置していきます。
カテゴリラベルに加えて、類似性の尺度は色んな方法で分ける事が出来る
可能性があります。
例えば、身長や顧客の消費習慣に基づいて人をグループ化する事もあります。
次の章でも触れていきますが、合理的なクラスターが何であるか
分かりやすい概念についても見ていきましょう。
ラベルなしデータのクラスタリング
次に、ラベルのないデータをクラスター化する方法を見ていきます。
基本的に、これはラベルのない(答えのない)データを同じグループに分割すること
を意味します。
データに予めラベルが付けられている場合、グループ分けは簡単でしょう。
まず、いくつかのラベルのないデータを作成していきましょう。
今回は視覚化しやすいために、2次元に制限します。
points_per_class = 100
#クラスタの個数kを指定しなければならない↑
#Generate four clusters.
mean = [5,5]
cov = [[1,0],[0,1]]
x_one = np.random.multivariate_normal(mean, cov, (points_per_class))
y_one = np.full*1
y_two = np.full*2
y_three = np.full*3
y_three = np.full*4
y_four = np.full((points_per_class),0)
X = np.concatenate((x_one,x_two,x_three,x_four),axis=0)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
#Plot the data
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()

各データポイントのクラスラベル(色)はありませんが
パッと見てデータが分割していることが分かります。
パッと見てデータが分割していることが分かります。
4つのクラスターがあり、それぞれがデータの異なるクラスだといえるでしょう。
#ラベルを加える
y_one = np.full((points_per_class),1)
y_two = np.full((points_per_class),2)
y_three = np.full((points_per_class),3)
y_four = np.full((points_per_class),4)
Y = np.concatenate((y_one,y_two,y_three,y_four),axis=0)
#Plot
plt.scatter(X[:, 0], X[:, 1], c=Y, s=20, edgecolor='k')
plt.show()

上記の例は簡単に分割でき、データを視覚化できたので、かなり明確な境目がありました。
しかし、実際のデータはもっと判別がつきにくいものが多いです。
次回は少しまぎらわしい例も併せてみてみましょう。
もっと本格的に勉強したい!という人は、ぜひ現役プロの力を利用して
効率的に勉強する事をオススメしています。
ぜひ無料説明会等で話を聞いて、検討してみてくださいね^^
最後まで読んで頂きありがとうございました。
*1:points_per_class),0)
mean = [-5,-5]
cov = [[1,0],[0,1]]
x_two = np.random.multivariate_normal(mean, cov, (points_per_class
*2:points_per_class),0)
mean = [0,0]
cov = [[0.25,0],[0,0.25]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class
*3:points_per_class),1)
mean = [4,-2.5]
cov = [[0.25,0],[0,0.25]]
x_three = np.random.multivariate_normal(mean, cov, (points_per_class
*4:points_per_class),0)
mean = [-6,2.5]
cov = [[0.25,0],[0,0.25]]
x_four = np.random.multivariate_normal(mean, cov, (points_per_class
【機械学習】教師なし学習-KMeans・ラベルなしデータ
こんにちは!EMです^^
今日からは教師なし学習について解説していきたいと思います!
機械学習に興味がある方なら、一度は聞いたことのある単語ではないでしょうか。
さっそく教師なし学習とはなにか、どうやって使うのかを見ていきましょう!
教師なし学習-KMeans
すべての統計と機械学習モデリングは、独立変数(観測値または特徴のセット)と
従属変数(結果)を持つデータに基づいています。
独立変数が従属変数を生じさせるある程度の出てきた効果を
私たちはゴールとして言い換えることができますが
この効果をどのようにモデル化して理解していくのでしょうか?
これまで、従属変数がどのように見えるか、それが取ることができる値の範囲
モデルを適合させるデータ(トレーニングセット)にどのような値がかかるかを
既に理解できているものだという前提を仮定しています。
また上記の内容は、答えありきのデータを使用して学習するという事で
教師あり学習として広く知られています。
そして今回からは、教師なし学習を学びます。
従属変数の値がないモデルを適合させる方法です。
それではいつも通り、パッケージをインポートしていきましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn as sk
from sklearn.metrics import accuracy_score
from sklearn import model_selection, metrics, linear_model, datasets,
feature_selection
ラベルなしデータ(Unlabeled Data)
ラベルなしデータとは、従属変数の値がわからないデータで
予想よりも頻繁に発生する可能性があります。
データにラベルを付けられない、いくつかの理由があります。
1.データが不適切に収集された場合(欠落または不正確なラベル)
2.データにラベルはないが、パターンが見つかる可能性がある場合
3.データには基礎となるパターンがあるが、これまでに遭遇したことがない為
注釈をつける事が難しい場合
いずれの理由でも、ラベルなしデータを処理および分析する方法を見つける必要があります。
今回は短いですが、ここで一区切りしようと思います。
次回以降はクラスタリング・PDA等を見ていく予定なので、盛沢山ですよ~!
ちなみに、今後データサイエンスを通じて、転職やキャリアップを考えている方に
ぜひ検討してみてほしいのがこちらです!
↓↓データミックス
かなり口コミもよさげで、講師陣も現役バリバリの人ばかりみたいです。
気になる方は、このデータミックスが提供しているコースの
メリットデメリット等も解説してみたので、併せてこの記事も参考にしてみてください^^
↓↓
machinelearningforbeginner.hatenablog.com
それでは最後まで読んで頂きありがとうございました~^^