~Backpropagation Algorithm~ バックプロパゲーション アルゴリズムってな~に?【保存版】
こんにちは^^EMです。
今日は機械学習の肝である、ニューラルネットワークの
興味ぶか~い内容をまとめました。
その名もバックプロパゲーション!!じゃーーん!!
はい、ここから本題です。
バックプロパゲーションアルゴリズムとは
ニューラルネットワークの最も基本的な要素です。
1960年代に初めて導入されて、ほぼ30年後(1989年)に
RumelhartさんとHintonさんとWilliamsさんが
“Learning representations by back-propagating errors”.
という書物でさらにバックプロパゲーションを盛り上げたようです。
このアルゴリズムはchain rule(難しい言葉でいうと’連鎖律’)
という方法で、ニューラルネットワークを超効果的に
トレーニングするために使用されます。
とっても簡単に言うと、Aさんが入り口から
色んな道を順番に通過して出口に着いた後
バックプロパゲーションという魔法の絨毯に乗って
入口まで戻ってくれるんです。
そして魔法の絨毯の何がすごいかというと、入口に戻る時に
weightsとbiasesというものを勝手に調節してくれて
次にAさんが同じ道に来た時に通りやすくしてくれんです!
そうする事でAさんが出口まで辿り着いたとき
より良い結果に繋がるんですよね。
この記事では簡単な例として、4レイヤーの
ニューネラルネットワークのトレーニングと最適化を
数学を交えながらそのプロセスを説明していきたいと思います。
ぜひバックプロパゲーションがどうやって動いているのか
理解しながら、このすごさを感じて下さい!
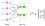
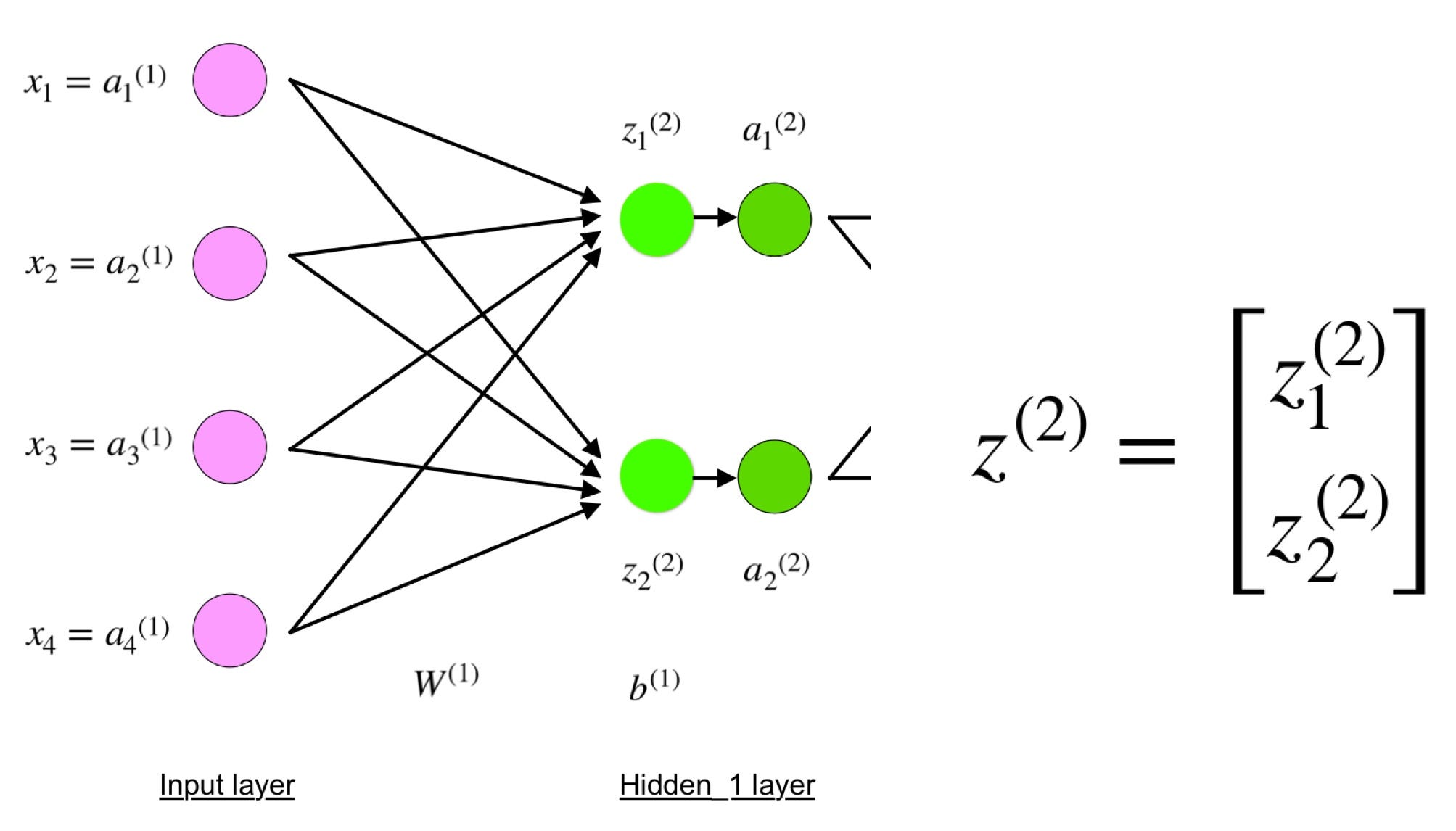
ニューラルネットワークモデルを定義する
4レイヤーのニューラルネットワークは、
入口(入力層)の4つのピンクのニューロン
真ん中(隠れ層)の緑の4つのニューロン
出口(出力層)の青い1つのニューロンで表されています。
※ニューロンとは下記の図でいうと丸の事を指しています。

入力層(input layer)
ピンクのニューロンは、入力データを表します。
入力データは単純な数字の場合もあれば
ベクトルや多次元行列のように複雑な場合もあります。
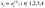
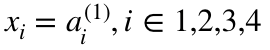
隠れ層(hidden layer)
緑色の隠れ層といわれる値はZ ^ Lを使って計算されています。
Z ^ Lというのはlayer lにweightsを加えられた値
a^lは活性化関数ですね。
そしてlayer 2 やlayer 3の計算式は次のとおりです。
- l = 2
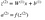
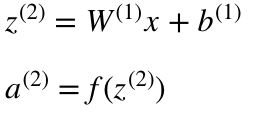
- l = 3
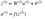
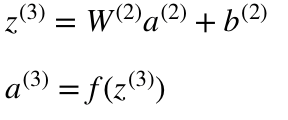
W²とW³はレイヤー2と3のweightsで、
b²とb³はこれらのレイヤーのbiasです。
Activationsのa²やa³は、活性化関数 f を使って計算されます。
大抵の場合は、この関数fは非線形
(シグモイド、ReLU、tanhなどS字のような直線ではない形)です。
この関数を使用する事によってネットワークが
データの複雑なパターンを学習できるようにします。
活性化関数がどのように機能するか詳しく気になる方は、
ところで、上の4レイヤーの図をよ~く見ると x、z²、a²、z³、a³、W¹、W²、b¹、b²全て
色んな数式が文字にくっついたりするのではなく、全部シンプルに表されてますよね。
これはレイヤーごとにグループ分けされた行列(※5)内の
全パラメーター(※6)値を組み合わせられた為です。
これはニューラルネットワークを使う一般的な方法です。
理解を深めるために、ぜひこの方程式や計算にも慣れていきましょう!
ではでは一例として、レイヤー2とそのパラメーターをみてみましょう。
一度理解すると、同じ考え方で他のレイヤーにも応用する事ができます。
・W¹はshape(n,m)の重み行列です。
ここでnは出力ニューロン(次のレイヤーのニューロン)の数、
mは入力ニューロン(前のレイヤーのニューロン)の数です。
今回の場合、n = 2、m = 4となります。
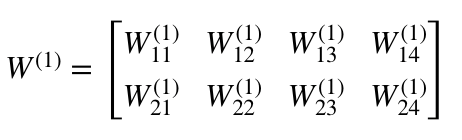
注:
weightの添え字の最初の数値は次のレイヤーのニューロンの
インデックスと一致しています。
(この場合、Hidden_2layerです)
また2番目の数値は、前のレイヤーのニューロンのインデックスと
一致します。(この場合、Input layerです)
- xはshape(m、1)の入力ベクトルです。ここでのmは入力ニューロンの数となります。今回の場合、m = 4です。

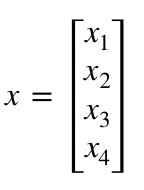
- b¹はshape(n、1)のbias ベクトルです。ここでは、nは現在のレイヤーのニューロンの数です。 今回の場合、n = 2です。
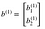
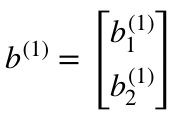
z²の式に従って、上のW¹、x、b¹の定義を使って、’z²の式’を導き出すことができます。

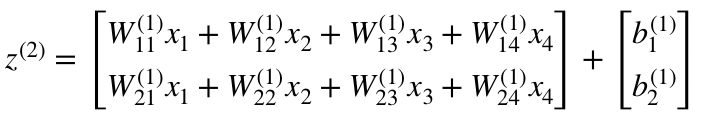
それでは上記をふまえてニューネラルネットワークをみてみましょう。
z²は(z_1)²と(z_2)²を使って表すことができます。
(z_1)²と(z_2)²は、入力層であるx_iと
weight(W_ij)¹をかけ合わした合計になります。
これによって同じ「z²の方程式」が分かり、z²、a²、z³、a³の
行列表現が正しいという事が証明されます。
出力層
ニューラルネットワークの最後は、述語値をつくる出力層です。(述語とは値によって真か偽かがきまる、ひらたくいうと答えの事です。)
今回の1番初めの例でいうと
単体の青色のニューロンが下の式を表しています。
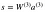
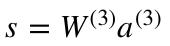
ここでも、方程式を簡単にするために行列表現を使っています。
上記の方法で、基礎となるロジックを少しでも理解してもらえれば
うれしいです。
フォワードプロパゲーションと評価
上の方程式は、ネットワークのフォワードプロパゲーションをつくります。 ざっくりとした概要は次のとおりです。


フォワードパスの最後のステップとして、期待されていた出力層の値yに対して、述語の出力層sを評価することです。
sとyの評価は損失関数によってみる事が出来ます。
これはMSE(平均二乗誤差)くらいシンプルで、交差エントロピーよりも複雑です。
この損失関数は’C ’と表され、次のような式を書く事ができます。
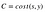
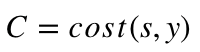
costは、MSE、クロスエントロピー、その他のどんなコスト関数とも
イコールになることがあります。
Cの値から、そのモデル自体が理想の出力層yに近付くために
どれだけパラメータを調整すればいいのか判断してくれます。
これがバックプロパゲーションアルゴリズムです。
バックプロパゲーションと勾配の計算
1989年の記事によると、バックプロパゲーションとは
repeatedly adjusts the weights of the connections in the network so as to minimize a measure of the difference between the actual output vector of the net and the desired output vector.
(日本語訳)
ネットの実際の出力ベクトルと理想の出力ベクトルとの差の測定値を最小化する為に、ネットワーク内の接続の重みを繰り返し調整します。
the ability to create useful new features distinguishes back-propagation from earlier, simpler methods…
(日本語訳)
有用な新機能を作成する機能は、バックプロパゲーションを以前のより単純な方法と区別します…
分かりやすくいうと、バックプロパゲーションは
ネットワークのweightとbiasを調整することにより
コスト関数を最小化することを目的としています。
どの程度調整されるかは、パラメーターに関する
コスト関数の勾配によって決まります。
ここで疑問なのが…
なんで勾配の計算をするのか?
その答えを見つける為に、微積分をもう一度確認しましょう。
- 点xの関数C(x_1、x_2、…、x_m)の勾配は
xの中にあるCの偏導関数のベクトルです。 - Gradient of a function C(x_1, x_2, …, x_m) in point x is a vector of the partial derivatives of C in x.
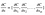
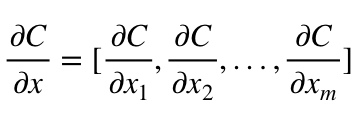
- 関数Cの導関数は、引数x(入力値)の変化に対する
関数値(出力値)の変化に対する感度を測定します。
つまり、導関数はCが進む方向を示します。 - 勾配は、Cを最小化するためにパラメーターxを
(正または負の方向に)変更する必要がある量を表します。
この勾配の計算は、連鎖律(chain rule)というテクニックを使って行われます。
この単一のweight (w_jk)^lであれば、勾配はこのようになります。


似たような方程式は (b_j)^lにも当てはめる事ができます。


どちらの方程式も「局所勾配」と呼ばれることが多く
よく次のように表されます。
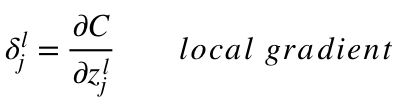
局所勾配の方程式
「局所勾配」は、連鎖律を使用して簡単に決められます。
今回はくわしく取り上げませんが、気になる方がいれば
コメントを頂けると嬉しいです。
この勾配はモデルのパラメータを最適にしてくれます。


- WとBの初期値はランダムに設定されます。
- イプシロン(e)は学習率です。勾配の影響を決めます。
- w と bはweightとbiasの行列表現です。wまたはbのCの導関数は、各々のweightやbiasのCの偏導関数をつかって計算できます。
- コスト関数が最小化されると、終了条件が満たされます。
最後になりますが、単一のweight(w_22)²に対するCの勾配を
計算するシンプルな例をあげたいと思います。
上記のニューラルネットワークの下の部分をみてみましょう。

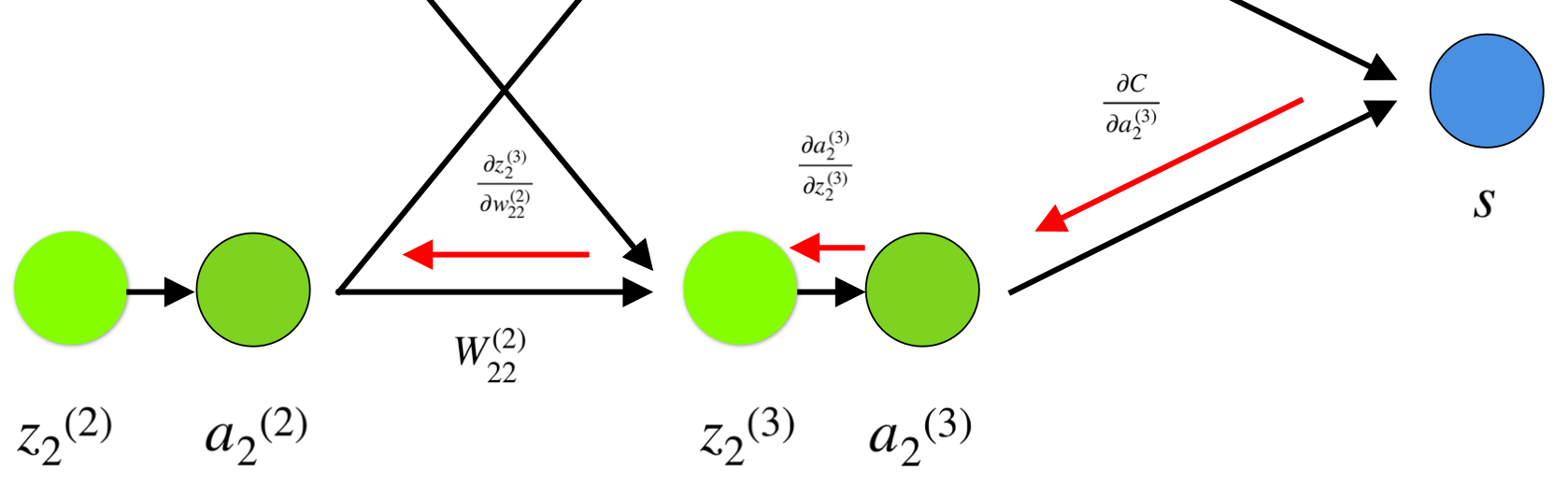
ニューネラルネットワーク内でのバックプロパゲーションの視覚的表現
Weight (w_22)² が (a_2)² と(z_2)²に繋がって
(z_2)³ と(a_2)³を通って勾配の計算をするには
連鎖律に当てはめる必要があります。

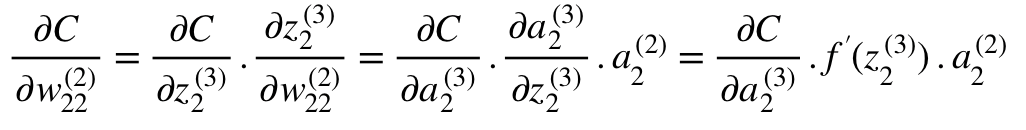
(w_22)²の導関数の方程式
(a_2)³でCの導関数の最終値を計算するには
関数Cを理解する必要がありますが
Cは(a_2)³に依存しているため、導関数の計算はかなり単純です。
上記の説明が、勾配の計算の理解につながれば幸いです。
より詳しい解説は、リチャード・ソーチャー氏が
バックプロパゲーションについて4つのすばらしい説明をしているので
スタンフォード大学のNLPシリーズをぜひ見てみて下さい。
この記事では、勾配の計算や連鎖律などの数学的手法を使用して
内部でバックプロパゲーションがどのように機能するかについて
詳しく説明しました。
このアルゴリズムの要点を理解することで
ニューラルネットワークの知識が強化され
このアルゴリズムが使いやすくなれば幸いです。
めちゃくちゃ奥が深いモデルですが
引き続きディープラーニングを理解していきましょう!
ちなみに皆様に2点、朗報です!
未経験からでも大丈夫!
スキルアップしながら、学校にいくお金を節約+お給料をもらえる仕事を紹介してくれる
夢のようなサイトがあります。
それが「IT求人ナビ」です!
↓↓

今後、エンジニアやWEBデザイナー等でキャリアを築こうとしている方
IT求人ナビの就職のプロが相談にのってくれるので
企業の実態の話を聞けたり、ブラック企業を避ける事ができるという点でも
今後の参考になると思います!
今後もディープラーニングをはじめ、様々な事を解説していこうと思いますが
もし、もっと効率よく、実践のビジネスの場に繋げられる様に勉強したい!という方に
おススメの講座を見つけたので、気になる方はぜひ無料説明会を通じてみてみてください!!
↓↓

データミックスでは、様々なケーススタディ等を通じて、未経験からでも
6か月でデータサイエンティストを目指せるコースや、基礎固めのコースなど
データ分析の内容を中心に、様々なプログラムを開講しています!
もしサクッと情報を収集したいという方は、このコースについて
メリットデメリットをまとめた記事もあるので、そちらも参考にしてみてください。
machinelearningforbeginner.hatenablog.com
最後まで読んで頂きありがとうございました^^