SQLってな~に??

こんにちは^^EMです。
みなさんSQLって聞いた事ありますか?
今日は知ってて損する事はない、機械学習やデータサイエンスにおいて基本となるSQLの知識についてお話しようと思います!
SQL(Structured Query Language) は
データサイエンティストの道具箱のような存在で
とっても重要なツールです。
SQLを学ぶことは、機械学習の入門者として
不可欠かつ、複雑な問題も解決できることができます。
SQLを理解することで、周りの人からも抜きんでる
存在になることは間違いなしです。
この記事では、5つのよくあるクエリと
それを解決するアプローチについて
ご説明します。
Note — 各クエリはさまざまな方法で解決する事ができます。 この中に書いてある答えに進む前に、あなたならどんなアプローチが出来るか考えてみてください。 コメントにてこの記事にはない様々なアプローチもお待ちしています。
クエリ 1
※クエリとはデータベースに対する命令文、または検索キーワードです
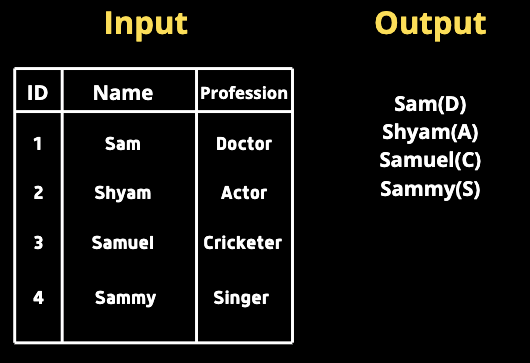
下の表が与えられました。
NameとProfessionの2つの列で構成されています。
名前の直後に()内に職業の最初の文字が
くるようにする必要があります。
【回答例】
SELECT
CONCAT(Name, ’(‘, SUBSTR(Profession, 1, 1), ’)’)
FROM table;
【解説】
名前と職業を組み合わせる必要があるため
CONCATを使用しました。
また()内に1文字だけ職業名を含める必要があります。
したがって、SUBSTRを使用して、列にある名前と
インデックスと部分文字列の長さを渡します。
この場合だと、最初の文字のみが必要なので
1,1となっています。
クエリ 2
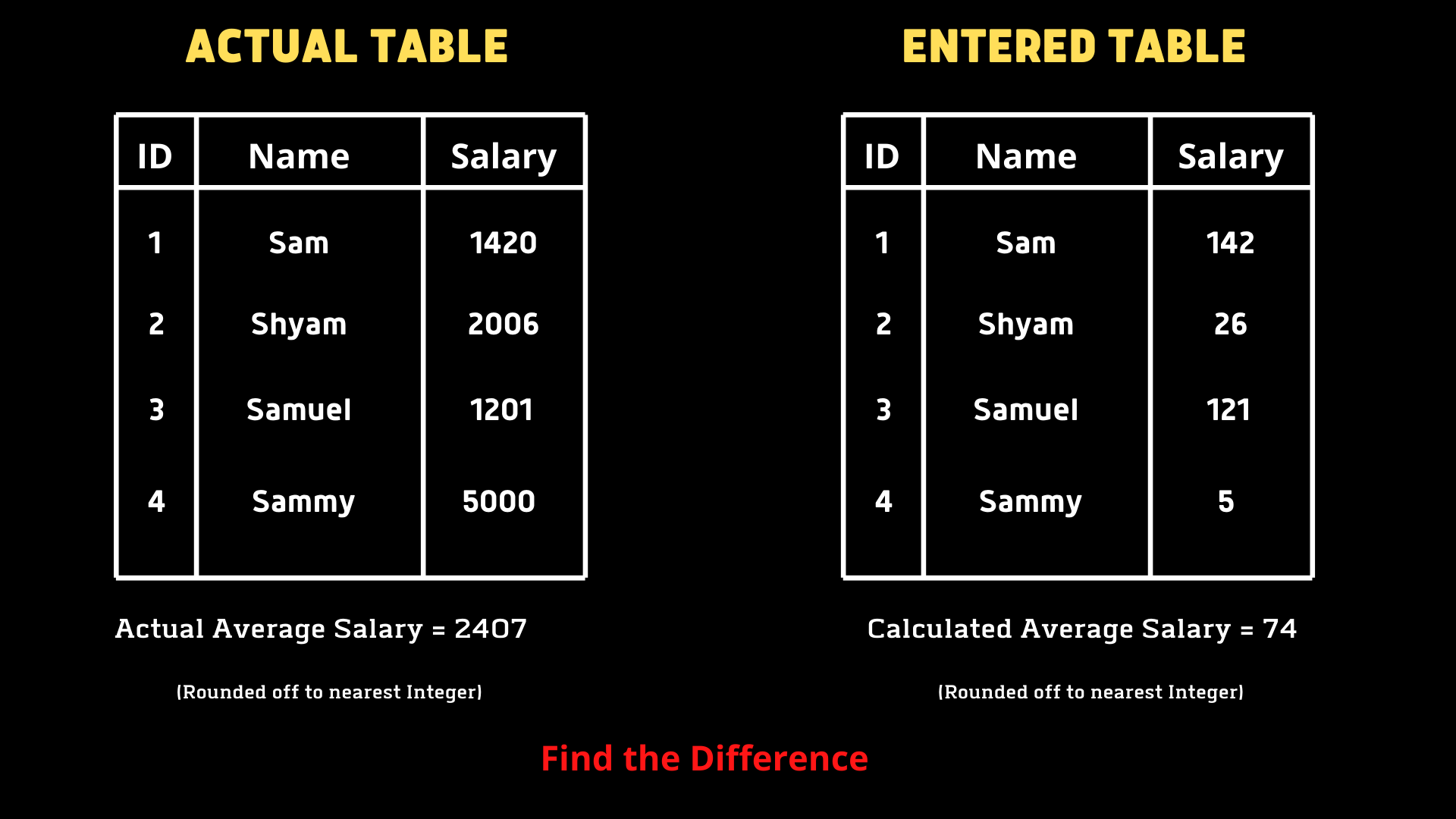
Tinaさんは、上司からEMPLOYEESの表をもとに
従業員の平均給与を計算するように
指示されました。
しかし計算した後、結果がかなり低い平均を示し
Tinaさんはキーボードのゼロキーが
機能していなかったことに気付きました。
Tinaさんは、私たちのヘルプが必要です。
誤って計算された平均と実際の平均の違いを見つけるために、 エラーを見つける解決策を考えてみましょう。
回答例
SELECT
AVG(Salary) - AVG(REPLACE(Salary, 0, ’’))
FROM table;
ここでの注意ポイントは、実際の給与の値を示した
表は1つしかないということです。
エラーシナリオを作成するには、REPLACE を使用して
0をおきます。
列名(ここではsalary)、0、REPLACEメソッドを適用する値を書きます。
次に、集計関数AVGを使用して平均の違いを見つけます。
クエリ 3
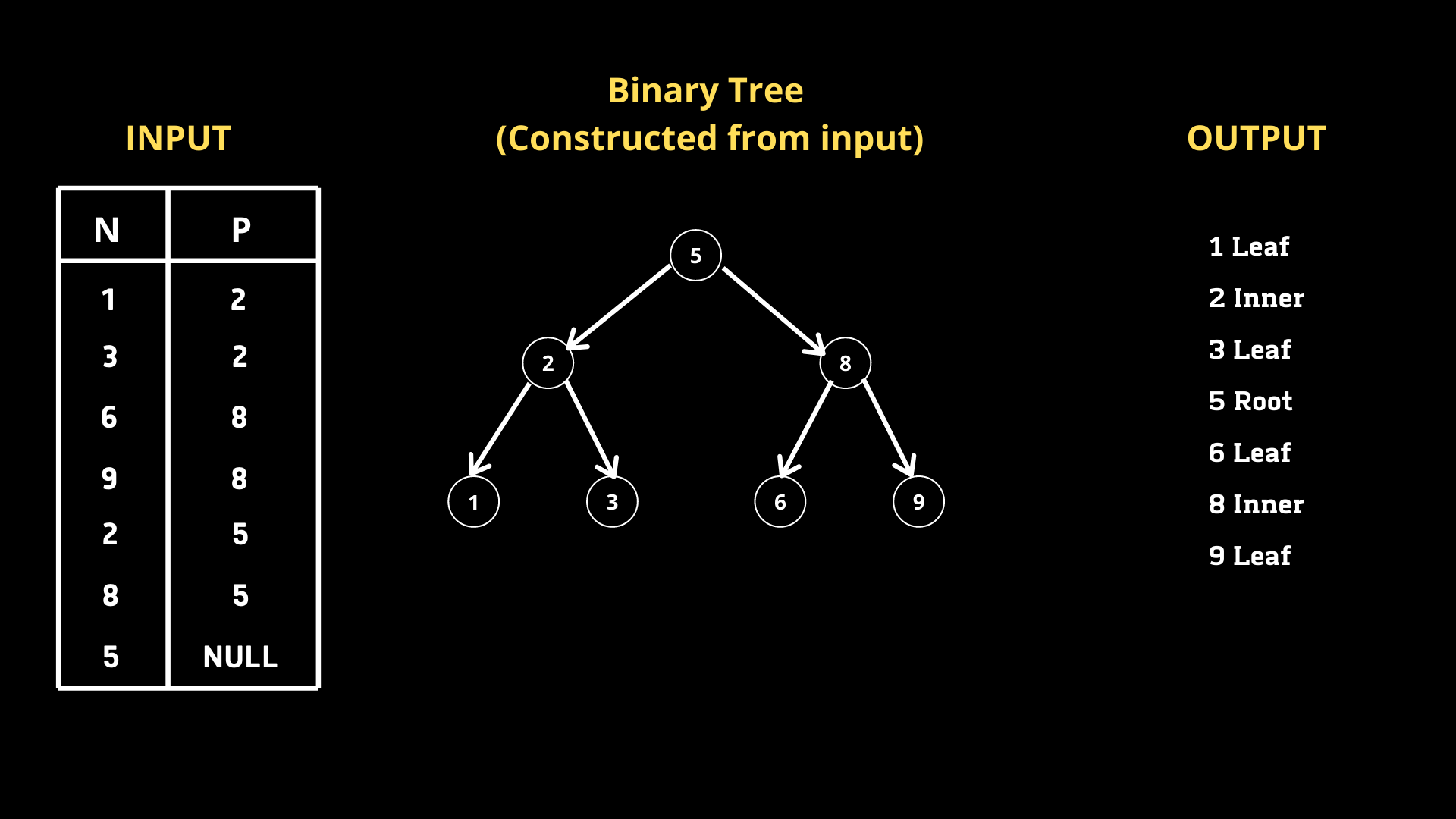
NodeとParentの2つの列でつくられた
Binary Search Tree(二分探索木)があります。
そこで、Nodeの値の小さい順で並べられた
Nodeタイプを返す命令を指示しなければいけません。
これには3種類の方法があります。
1.Root —Nodeがrootの場合
2.Leaf —Nodeがleafの場合
3.Inner —nodeがrootでもleafでもない場合。
回答例
まず、特定のノードNの対応するP値が
NULLである場合、それがルートであると
結論付けることができます。
また特定のノードNがP列に存在する場合
それはinnerノードです。
この考えに基づいて、指示をつくりましょう。
SELECT CASE
WHEN P IS NULL THEN CONCAT(N, ' Root')
WHEN N IN (SELECT DISTINCT P from BST) THEN CONCAT(N, ' Inner')
ELSE CONCAT(N, ' Leaf')
END
FROM BST
ORDER BY N asc;
ここでは、スイッチ機能として動く
CASE を使用します。
上記でもあったように、与えられたノードNに対してPがnullの場合、Nがルートになります。
そのため、ノード値とラベルを組み合わせるためにCONCATを使用しました。
同様に、特定のノードNがP列にある場合
それはinnerノードになります。
P列からすべてのノードを取得するために
P列の全個別のノードを返すサブ命令を
作成しました。
ノード値で出力を小さい順で並べ替えるように
求められたため、ORDER BY句を使いました。
クエリ 4
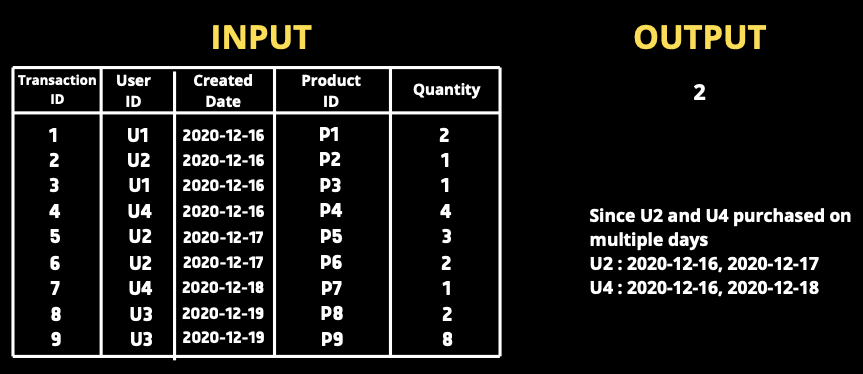
transaction_id、user_id、transaction_date、product_id、quantityで構成されている
処理(transaction)の表があります。
数日間にわたって製品を購入したユーザーの数を
見つけたいです。
(ユーザーは1日に複数の製品を購入できます)
回答例
user_idは直接数えることはできません。
ユーザーは1日に複数の処理を実行できるため、user_idが複数返されます。そのため、user_idに複数の異なる日付が関連している場合
そのユーザーは複数日に製品を購入したことになります。
同じアプローチを使って、クエリを作成しました。 (innerクエリ)
SELECT COUNT(user_id)
FROM
(
SELECT user_id
FROM orders
GROUP BY user_id
HAVING COUNT(DISTINCT DATE(date)) > 1
) t1
今回の質問ではuser_id自体ではなく
user_idの数が求められたため、outerクエリで
COUNTを使用しています。
クエリ 5
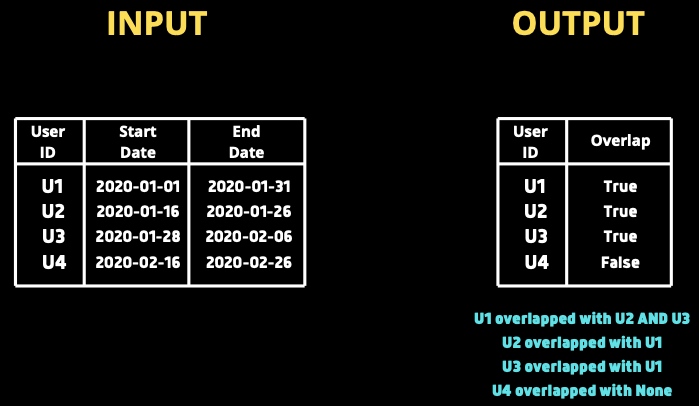
各ユーザーのサブスクリプションの開始日と終了日で構成される表があります。
他のユーザーと日付が重複している事に基づいて
ユーザーごとにtrue / falseを返すクエリを作成したいです。
たとえば、user1のサブスクリプション期間が他のユーザーと被っている場合
クエリはuser1に対してTrueを返す必要があります。
回答例
最初のステップとして、サブスクリプションを
他のサブスクリプションと比較する必要がありますよね。
userAの開始日と終了日を、startA と endA
同じようにuserBをstartB と endBと見なします。
もし startA≤endB かつ endA≥startB だとすれば
2つの日にちの範囲が重複していると言えます。
ここで2つの例を見てみましょう。
まず U1 と U3を比較してみます。
startA = 2020–01–01
endA = 2020–01–31
startB = 2020–01–16
endB = 2020–01–26
ここでは、startA(2020–01–01)が
endB(2020–01–26)よりも小さく、
同じように、endA(2020–01–31)がstartB(2020–01–16)よりも大きいことがわかります。
したがって日付が重複していると言えますね。
同様にU1とU4を比較すると、上記の条件は
falseを返します。
またユーザーが自分のサブスクリプションと
比較されないようにする必要があります。
さらに条件を満たすユーザーをお互いに
マッチさせる為に左結合を実行したいですよね。
ここで、同じ表の2つのレプリカs1とs2を作ります。
SELECT *
FROM subscriptions AS s1
LEFT JOIN subscriptions AS s2
ON s1.user_id != s2.user_id
AND s1.start_date <= s2.end_date
AND s1.end_date >= s2.start_date
条件付きの結合の場合、日付間に重複があるという条件で
s2のuser_idがs1の各user_idに存在する必要があります。
出力

日付が重複している場合は、ユーザーごとに
別のユーザーが存在することがわかります。
user1の場合、2人のユーザーと一致することを示す
2つの行があります。
ユーザー4の場合、対応するIDはnullであり
他のユーザーと一致しないことを示します。
全てを踏まえると、s1.user_idフィールドで
グループ化し、s2.user_idがNULLでないユーザーに
trueの値が存在するかどうかを確認できます。
あとひと踏ん張り!ファイナル クエリ!!
SELECT
s1.user_id
, (CASE WHEN s2.user_id IS NOT NULL THEN 1 ELSE 0 END) AS overlap
FROM subscriptions AS s1
LEFT JOIN subscriptions AS s2
ON s1.user_id != s2.user_id
AND s1.start_date <= s2.end_date
AND s1.end_date >= s2.start_date
GROUP BY s1.user_id
特定のユーザーのs2.user_id値に応じて
CASE 句を使って1と0というラベルを付けました。
最終的に出力は次のようになります。

最後に
SQLをマスターする事はたくさんの練習が必要です。
この記事の中では、5つのひっかけクエリを取り上げて
解決までのアプローチを説明しました。
今回の各クエリについては、他にもいろんな書き方が
あるというのも1つのミソです。
ぜひあなたのアプローチをコメントの中でも共有してください!
今日なにか新しい事を学んでもらえると幸いです^^
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。

ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思いますし
デザイナーやWEBデベロッパー用などのコースも幅広くあるようなので
興味があるコースをチラ見してはいかがでしょうか^^
もちろん、個人で勉強する事もできますが、挫折経験のある私の個人的な経験から
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
ではではhave a nice day!!