回帰分析とは③
こんにちは!EMです^^
今回も引き続き、回帰分析について理解していきますよ~!
ここでは少し、回帰分析についてよく出てくる言葉についてふれていきます。
予測
線形回帰の方程式があるなら、与えられたxの値に対して
データを予測するできます!予測というMLっぽいキーワードが出てきました。
コスト関数
回帰分析に関する課題は、その問いに対して「最適化」を目指すという事です。
その為にはコスト関数(予測値と実際の値の間の誤差)を最小化していく事を
ゴールにします。
線形回帰問題のよく見かけるコスト関数(J)として
平均二乗誤差(MSE)があります。

予測は係数と独立変数から求める事が出来ます。

線形回帰係数の解は、コスト関数を最小化する解です。
最急降下法(Gradient Descent)
OLS線形回帰の問題には closed form solution(閉形式の解)がありますが
大抵のコスト関数を最小化にする問題に関しては
閉形式の分析的な解決法がありません。
その代わり数値的に推定していく為には、反復アルゴリズムに頼る必要があります。
この最適化アルゴリズムを最急降下法と呼びます。
概念的に最小化とは、コスト関数のグラフで1番低い点を見つけることです。
もしあなたが丘の高い場所に立っていて、下りの階段を下りていく事で
1番低い場所(最小点)を見つけることができますよね。
階段が常に下り坂である限り、丘のふもとにかならず到着します。
「各階段を下り坂にする」というのを数学的に言えば
「導関数」の方向、またはすべての点で線に接するタンジェント(tangent)です。
複数の変数がある場合、一般的に導関数は「勾配」と呼ばれ
各変数に関する偏導関数によって決まります。
デカルト座標のx、y、zでは、次のとおりです。

文系出身の人には、頭がいたくなりそうな、新しい記号がでてきましたね~。
▽はnablaと言われ、ベクトル計算を行う時に使われるそうです。
▽はシンプルに勾配を表しているみたいですね。
詳しくはWikipediaを見てみて下さい。
コスト関数Jの勾配は、常にJの勾配が0に等しい最小点に向かって
表面に接する点を指します。
どの時点からでも、小さなステップを踏むことで、最小値に向かって繰り返し
「歩く」ようなイメージですね。

ステップサイズ(学習率)が大きすぎると、最小値を見逃して反対側にいってしまう
可能性があります。
逆にステップサイズが小さすぎると、解を得るまでに
非常に長い時間がかかる場合があります。
Gradient Descent for OLS linear regression
さて、コスト関数で出てきた数式をもう一度みてみましょう。

2つのパラメータ(β0とβ1)を持つ線形回帰コスト関数Jの勾配は
連鎖律を使って求められます。

最急降下法を使用すると、どんなコスト関数でも数値的に解く事が出来ます。
最初は仮説をたてた状態で始めて、誤差と勾配を計算します。
次に、勾配の方向に「歩く」事を繰り返し、エラーを再計算していきます。
許容範囲内の解におさまるまで実行し続けます。
ぜひご自身の端末でも試してみて下さいね!
ヒントはこちら↓
x = np.random.normal(size = 100)
y = 3 * x + np.random.normal(scale = 3, size = 100) + 2
N = len(x)
cost_history = []
num_iterations = 500
learning_rate = 0.01
beta_0 = 0
beta_1 = 0
for each_iteration in range(num_iterations):
beta_0_deriv = 0
beta_1_deriv = 0
for i in range(N):
# Calculate partial derivatives
# -2x(y - (beta_1*x + beta_0))
beta_1_deriv += -2*x[i] * (y[i] - (beta_1*x[i] + beta_0))
# -2(y - (beta_1*x + beta_0))
beta_0_deriv += -2*(y[i] - (beta_1*x[i] + beta_0))
# We subtract because the derivatives point in direction of steepest ascent
beta_1 -= (beta_1_deriv / N) * learning_rate
beta_0 -= (beta_0_deriv / N) * learning_rate
#Calculate cost for auditing purposes
total_error = 0.0
for i in range(N):
total_error += (y[i] - (beta_1*x[i] + beta_0))**2
cost = total_error / N
cost_history.append(cost)
# Log Progress
if each_iteration % 10 == 0:
print ("iter={:d} beta_1={:.2f} beta_0={:.4f} cost={:.2}".
format(each_iteration, beta_1, beta_0, cost))
print ('beta_0: '+ str(beta_0))
print ('beta_1: '+ str(beta_1))
plt.scatter(x,y)
plt.plot(x, beta_1*x + beta_0)
エクササイズ
上記のコードを関数に変換していきましょう!
def gradient_descent_linear_regression (X_vals, y_vals):
# fill in function code here:
return Betas # a tuple of beta_0, beta_1
少し長くなりましたが、じっくり一つ一つ理解していきましょう!
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。

ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思っているので
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
それではまた次回~!^^
回帰分析とは②
こんにちは!EMです^^
今回は回帰分析の第2弾という事でやっていきたいと思います。
まず線形回帰について触れていきたいと思います。
線形回帰とは、最小二乗回帰(OLS: Ordinary Least Squares)とも呼ばれています。
最適な線からの二乗の差を最小化にしたいときに使われ、下記のような
係数を直接計算できる線形回帰の方程式を利用します。
(数学的には closed-form solutionというそうです。)
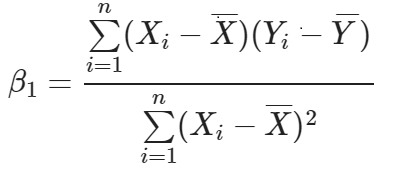
傾きが分かれば、切片も計算できます。

残差(Residuals)
線形回帰をもう少し理解する為のもう1つの方法は
グラフに線を引いて、その線への残差平方和を最小化するという事です。
fig, ax = plt.subplots(1,2)
sns.regplot('x', 'y', pd.DataFrame({'x':x, 'y':y}), ax = ax[0]);
sns.residplot('x', 'y', pd.DataFrame({'x':x, 'y':y}), ax = ax[1]);

少し数学的な話がでてきたので、特に初心者の方からすると
一気に難易度があがったかと思います。
でも回帰分析を理解する上で、基礎を抑えるのはとても重要です。
今日はここまでにして、また次にも回帰分析について説明を加えたいと思います。
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。
ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思っているので
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
ではまた~^^
回帰分析とは①
こんにちは!EMです^^
本日は回帰分析とはなんぞや?という話をしていきたいと思います。
回帰分析を理解する為に、おさえていきたいのが下の二つ。
・コスト関数やエラー
・反復解法、最急降下法
なにやら難しい単語が出てきましたね。
はじめて見る方には抵抗感しかないかもしれません。
こちらは次回以降に解説していこうと思います。
まず、回帰分析の一種で線形回帰というものがあります。
名前は難しいですが、見た目は棒線グラフです。
線形回帰とは2つの連続した数(変数とも言います)の関係を表す方法です。
相関係数とは2変数との関係の強さを表しますが
一方で、線形回帰を使用すると、それらの間の関係を描いて
従属変数の新しい値を予測できます。
※従属変数とは独立変数の変化に応じて変わる値です。
基本的な線形回帰は、従属変数を相互の値に応じてモデル化します。
これはデータを通じて「ベストな線」を描くための統計的手法になります。
import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
pd.options.display.max_columns=500
import warnings
warnings.filterwarnings("ignore") #warning suppressor
x = np.random.normal(size = 100)
y = 3 * x + np.random.normal(scale = 3, size = 100) + 2
sns.lmplot('x', 'y', pd.DataFrame({'x':x, 'y':y}));
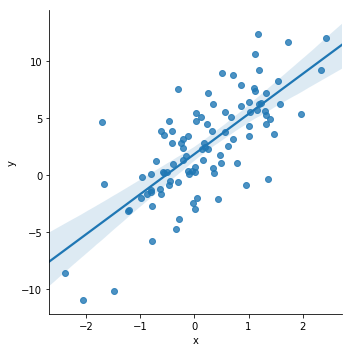
従属変数のyと独立変数xの関係は数式でこのように記述できます。
y=β0+β1X+ϵ
ここで、β0は切片、β1は勾配(傾き)、ϵ がランダムエラーを表します。
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。
ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思っているので
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
これからどんどん内容がMLっぽくなっていきますよ~!
では次回お楽しみに^^
The Social Dilemma(監視資本主義 デジタル社会がもたらす光と影)をみた感想
こんにちは!EMです^^
今回は趣向を変えて、テクノロジーに関する映画をみたので
MLがどの様に使われているのか、エンジニアでさえ恐怖だと思っている
テクノロジーが人に与える影響について、私の個人的な意見も交えながら
お伝えしていきたいと思います。
今回紹介したい映画は
「The Social Dilemma(監視資本主義 デジタル社会がもたらす光と影)」
です!完全にネタバレがありますので、ご注意ください。
~あらすじ~
元大手のエンジニア達によるインタビューを基に作られたドキュメンタリーです。SNSやネットを使うことが当たり前になっている現代の私たちへ、どの様にネットやテクノロジーと向き合っていくべきなのか、めちゃくちゃ考えさせられる内容です。
インタビューと、エンジニア達がどの様に人を行動を操っているのかという再現ドラマがあり、ざっくりとIT企業(映画の中ではグーグル、インスタ、Facebook等の話が多いです)がどの様な事を一般人に仕掛けているのか大変分かりやすいです。
ただその反面、SNSを使用する側の立場もかなりリアルに描かれています。
自分の意思で観ていると思っているスマホやネットの中の映像は、大企業の膨大なデータによって全てコントロールされているのかもしれません。
’No one is an evel’
どんな企業やエンジニアも、悪意があって人をコントロールしているのではありません。それでも、お金の為に人の行動を把握、予測したい企業がやっている事は、結果的に人々へ悪影響を及ぼすこともあります。
この映画で描かれているのは、「この男の子はクラスメートの女の子が好き」という感情を悟ったエンジニア達が、その恋心を利用して巧みに通知や色んなコンテンツを男の子に与えます。結果、エンジニアのSNSに引きずり込もうという作戦が成功し、男の子は結局その女の子との恋も実らず、SNSに集中してしまい、最終的にはデモ活動に巻き込まれてしまう、、という少し悲しいストーリーです。この話の流れは少し極端かもしれませんが、この男の子と似たような深層心理はめちゃくちゃ我々の日常でも起こり得ると思っています。
~感想~
ML(機械学習)をもっと知りたい!という私の個人的な意見として、MLの短所や、MLがもたらす影響はエンジニア以外も知っておかないといけない使命だと思っています。
というのも、どんな賢い大人でさえSNSやネットに振り回される可能性はあるからです。そんな事実がある中、どうやって若い世代が自分でSNSをコントロールできるのでしょうか?
GAFAに関わらず、今後ビックデータと精度の良いアルゴリズムを持っている企業はどんどん進出してくる事は間違いありません。そして彼らが得意なのは「人の無意識領域」の深~いところまではいっていく事です。
私が1番恐いと思った事は、もし誰かが自分を操っていると自覚したところで、多くの人はSNSを使い続けるという事です。今回の取材されていたエンジニアも「どんなけ自分のwill power(意思の力)を使っても、ベッドに入る時は必ず携帯を見てしまう」と答えています。私もこの映画を見た後でもやはりSNSやネットは見ます。
それでも私達は、この状況を自覚し、出来るだけ自分をコントロールし、自分の意思や意見を持つべきだと思っています。そして出来るだけ事実を正しく見る事。
ツイッターのニュースは普通のニュースに比べて約6倍速いそうです。特にコロナの発生により、多くのフェイクニュースに振り回された人も少ないと思います。また別の映画では、トランプ元大統領が当選した時の選挙は、SNSから意見を変えそうな人を抽出し、その人たちへアプローチをした事が当選に繋がったというケースもありました。そんな話をきくと、人は簡単に他人(又は企業)に左右されてしまうんだと感じます。繰り返しになりますが自分の意思、意見、事実を正しくみるという姿勢は本当にこの時代には必要です。
もう一つショッキングだったのは、アメリカの10代の女の子が自傷行為をし病院に搬送されたというケースが2009年以降それまでに比べて62%アップしているという事。他の要因はあるかもしれませんが、これは確実にSNSやネットの影響が大きいのではないかと思います。自分の10代の時を振り返ると、いじめや中傷はかなり身近に起きていたので、SNSやグループチャットのサービスが簡単に使える現代ではいじめがエスカレートしやすい環境であるという事は容易に想像出来ます。もし自分の子供が携帯が欲しいと言ってきたら、どの様な影響がとりまくのか、またそのサポートや対策も考える必要があると思います。長々と怖い面だけお伝えしましたが、もちろん携帯やネットの良い面もたくさんありますから、若い間にテクノロジーに触れさせるのも大切ですからね。
予定よりも私の感想が長くなってしまいましたが、とても考えさせられる内容だったのでぜひ機会があれば見てみて下さい^^
ちなみに皆様に朗報です!

これは、実践のビジネスの場でデータを使えるように指導してくれる
社会人の為の講座です!
社会人の為の講座です!
ぜひサイトや無料説明会等で情報を見てみてくださいね^^
また詳しくは簡単にメリットデメリット等もまとめているので
よかったら下の記事も参考にしてください^^
よかったら下の記事も参考にしてください^^
最後まで読んで頂きありがとうございました。
Matplotlibの使い方をみてみよう!⑦
こんにちは! EMです^^
さっそく、みなさんの2021年の抱負はありますか?
2020年以上に邁進していきたい!という方は多いんじゃないでしょうか。
私は昨日1年の抱負をいくつか考えていたんですが(年明けてから考えてます笑)
「1つは好きな時間に触れる時間を多くする」という事です。
この機械学習も私の好奇心の追及の一環としてはじめましたが
自分が何が好きなのかをはっきり自覚する事はとても大切だと思っています。
聞くと当たり前の事だと感じますが、今まではフィーリングとか
ぼやっと「これいいな~」くらいで、はっきりと自覚していない事が多かったんですよね。
でも好きな事との接触時間が長ければ長いほど、単純にハッピーになれる時間が
増えるという事なので、少しでも好きな事と積極的に関われる1年にしていきたい
と思っています^^
そしてこのブログを見て下さるみなさんも、機械学習やテクノロジーが
「好き」とか「興味がある」事のひとつだといいなと思う今日この頃です。
さて、いつも以上に前置きが長くなりましたが、本題に入りたいと思います。
先日はMatplotlibの応用を深堀していきましたね。
日付の書式設定(Date Formatting)
timeseries_1.csv のデータセットをもう一度読み込み
日付の書式設定を行ってみましょう。
df2 = pd.read_csv('timeseries_1.csv',index_col=0,parse_dates=True)
df2.head()
high列とlow列をプロットしてみます。fig = plt.figure()
plt.plot(df2.index,df2['high'],label='High', color='red')
plt.plot(df2.index,df2['low'],label='Low', color='blue')
plt.xlabel('Time', size=15)
plt.ylabel('Price',size=15)
plt.legend()
plt.xlim(df2.index[0],df2.index[-1])
plt.title('Futures Prices',size=18)
plt.grid()
plt.show()
Matplotlibは、軸ラベルの情報をまとめて、不要なものをすべて削除しようとします。
今回の場合、すべての価格は同じ日に起こっているため、時刻のみが表示されます。
日付時刻を少し斜めに傾けると、軸ラベルとして読みやすくなることがよくあります。
これは、コマンドfig.autofmt_xdate()を使って実行できます。
このコマンドは、x軸ラベルとして表示される日時を自動的にフォーマットします。
fig = plt.figure()
plt.plot(df2.index,df2['high'],label='High', color='red')
plt.plot(df2.index,df2['low'],label='Low', color='blue')
plt.xlabel('Time', size=15)
plt.ylabel('Price',size=15)
plt.legend()
plt.title('Futures Prices',size=18)
plt.grid()
fig.autofmt_xdate()
plt.show()
他の例として、時間の代わりに日付を使用していきましょう。
df3 = pd.DataFrame({'Temperature':np.random.randint(10,32,30)},
index=pd.date_range('2016-06-01',periods=30,freq='12H'))
fig = plt.figure()
plt.plot(df3.index,df3['Temperature'],label='Temp')
plt.xlabel('Time', size=15)
plt.ylabel('Temperature',size=15)
plt.legend()
plt.title('Temperatures on a 12 Hour Scale',size=18)
plt.grid()
plt.tick_params(axis='x', labelsize=10)
plt.xlim(df3.index[0],df3.index[-1])
fig.autofmt_xdate()
plt.show()
フォントサイズの目盛りラベルを大きくして、日付を水平のままにするのと比較してみましょう。
fig = plt.figure()
plt.plot(df3.index,df3['Temperature'],label='Temp')
plt.xlabel('Time', size=15)
plt.ylabel('Temperature',size=15)
plt.legend()
plt.title('Temperatures on a 12 Hour Scale',size=18)
plt.grid()
plt.tick_params(axis='x', labelsize=10)
plt.xlim(df3.index[0],df3.index[-1])
plt.tick_params(axis='x', labelsize=15)
#fig.autofmt_xdate()
plt.show()
マーカー(Markers)
For broken-line graphs, like we've been seeing, we can emphasize our actual data points by placing markers at their locations. A few common markers are (".",point),(",",pixel),("o",circle), and ("D",diamond). Alternatively, we can specify the linestyle as .- which gives a solid line graph with dots:
これまで見てきたような折れ線グラフの場合、マーカーをその場所に配置することで
実際のデータポイントを強調する事ができます。
いくつかの一般的なマーカーはこんな感じです↓
(".",point),(",",pixel),("o",circle), ("D",diamond)
または線種を.-として指定することもできます。
これにより、ドットで出来た実線グラフをつくる事が出来ます。
fig = plt.figure()
plt.plot(df1.index,df1['A'],'.-',label='Stock A', color='red',linewidth=1.4)
plt.plot(df1.index,df1['B'],label='Stock B',marker='o' ,color='green',linewidth=0.5)
plt.plot(df1.index,df1['C'],label='Stock C',marker='D', color='blue',linewidth=2)
plt.plot(df1.index,0*df1.index,color='black')
plt.xlabel('Days After First Trade', size=10)
plt.ylabel('Price',size=12)
plt.legend()
plt.title('Stock Prices',size=18)
plt.grid(b=True)
plt.xlim(0,49)
plt.show()
マーカーについて詳しく知りたい方は、ぜひmatplotlibの公式ページも見てみて下さい。
グラフ関数(Graphing Functions)
グラフ関数これまで見てきた例では、離散データセット(個別のデータセット)をグラフ化しています。
さて、ここで問題です。
もしsin(x)やe−x2などの連続関数が出てきたとき、どのようにグラフ化するでしょうか?
その答えは、x軸として細かい点をたくさん使い、一連のデータポイントを作っていく事です。
ポイント間を線で埋める事で、目に見えないくらい十分に細かい点と点の繋がりから
一連のグラフを作り事ができます。
これを実際に行うために、np.arange()関数を使用します。
(注:これは配置ではなく、範囲です)
この関数は、np.arange(start,end,step)という構文を使用して
均等なスペースポイントの連続をつくります。
np.arange(0,10,0.5)
t = np.arange(0.0, 1.0+0.01, 0.01)
s = np.sin(2*np.pi * t)
plt.plot(t, s)
plt.show()
ステップサイズを0.01から0.1に変更するとどうなるでしょうか?
また、先ほどグラフを調整した方法を使えば
数学の教科書に出てきそうなグラフのように見せることもできます。
また、先ほどグラフを調整した方法を使えば
数学の教科書に出てきそうなグラフのように見せることもできます。
t = np.arange(0.0, 1.0+0.01, 0.01)
s = np.sin(2*np.pi * t)
plt.plot(t, s)
plt.plot(t,0*t,color='black')
plt.xlim(0,1)
plt.grid()
plt.show()
大まかにグラフを滑らかに見せるため、0.01にステップサイズを保つといいでしょう。
t = np.arange(1.0, 100.0+1, 1)
l = np.log(t/2)
plt.plot(np.log(t))
plt.show()
0.1のサイズともぜひ比べてみて下さい。
t = np.arange(1.0, 100.0+0.1, 0.1)
l = np.log(t/2)
plt.plot(np.log(t))
plt.show()
These tools will allow us to graph both data sets and mathematical functions on the same graph, which will be a good way to visually inspect any models we create.
これらのツールを使用すると、データセットと数学関数の両方を同じグラフに示す事ができます。
これは、作成したモデルを視覚的に考察する上で便利で分かりやすい方法です。
これは、作成したモデルを視覚的に考察する上で便利で分かりやすい方法です。
ファイルの出力
プロジェクトの様々な場面で使用するため、作成したグラフをファイルに書き込むことができます。
これを行うにはplt.show()をコマンドplt.savefig('filepath')に置き換えます。
1つ注意しておく事は、生成される画像ファイルのデフォルトサイズはかなり小さいのですが
dpiを設定することでコントロールできるという事です。
デフォルトと先程の例で調整した出力結果を比較してみましょう。
fig = plt.figure()
plt.plot(df3.index,df3['Temperature'],label='Temp')
plt.xlabel('Time', size=15)
plt.ylabel('Temperature',size=15)
plt.legend()
plt.title('Temperatures on a 12 Hour Scale',size=18)
plt.grid()
plt.tick_params(axis='x', labelsize=10)
plt.xlim(df3.index[0],df3.index[-1])
plt.tick_params(axis='x', labelsize=15)
fig.autofmt_xdate()
plt.savefig('c:\\users\\Patrick\\default_dpi.png')
my_dpi=96
plt.savefig('c:\\users\\Patrick\\adjusted_dpi.png',dpi=my_dpi*2)
デフォルトの解像度は864x720ですが、調整済みの解像度は2304x1920です。
サブプロット(Subplots)
Matplotlibの素敵な機能の1つとして、同じ画像に複数のグラフを出力できることです。
これはgridspecを使用してサブプロットを作成することで可能になります。
まずGridSpec(rows,columns)を使用してサブプロットのサイズを宣言し
下記の様にplt.subplot2grid()を使用して個々のデータをプロットします。
GridSpec(number of rows, number of columns)plt.subplot2grid((grid rows, grid columns),
(plot row position, plot column position))plt.plot(x,y)
df2(冒頭に定義しています)からhighとlow列の両方をプロットします。
その為2つの行と1つの列があり、位置が(0,0)と(1,0)になります。(0から数える)
import matplotlib.gridspec as gridspec
fig = plt.figure()
# set up subplot grid; 行と列がいくつあるか設定する
gridspec.GridSpec(2,1)
plt.subplot2grid*1# (2,1) = 合計のplotサイズ, (0,0)=このプロットが指定される
plt.plot(df2.index,df2['high'],label='High', color='red')
plt.xlabel('Time', size=12)
plt.ylabel('Price',size=12)
plt.legend()
plt.xlim(df2.index[0],df2.index[-1])
plt.title('Futures Prices',size=18)
plt.grid()
fig.autofmt_xdate()
plt.subplot2grid*2
plt.plot(df2.index,df2['low'],label='Low', color='blue')
plt.xlabel('Time', size=12)
plt.ylabel('Price',size=12)
plt.legend()
plt.xlim(df2.index[0],df2.index[-1])
plt.grid()
fig.autofmt_xdate()
plt.show()
We can even make more complicated arrangements by stretching graphs over multiple columns. We'll make a subplot of the volume, open, and close prices; the volume will by 2x2 rows and columns, and each of the open and close will be 1x1 underneath. We stretch by
グラフを複数の列に拡大することで、さらに複雑な操作を行うこともできます。
ボリューム、始値、終値のサブプロットを作成します。
ボリュームは2x2の行と列で、始値、終値はそれぞれ1x1以下になります。
ボリューム、始値、終値のサブプロットを作成します。
ボリュームは2x2の行と列で、始値、終値はそれぞれ1x1以下になります。
↓このコードによって拡大する事が出来ます。
plt.subplot2grid((r1,c1),(px,py),colspan=n,rowspan=m):gridspec.GridSpec(3,2)
# 3rows, 2columns.
#The volume will be at position (0,0) and will span 2 rows and 2 columns.
#The open and close will be at positions (2,0) and (2,1), and will be normal sized.
#The volume will be at position (0,0) and will span 2 rows and 2 columns.
#The open and close will be at positions (2,0) and (2,1), and will be normal sized.
plt.subplot2grid*3
plt.plot(df2.index,df2['open'],label='Open', color='red')
plt.xlabel('Time', size=12)
plt.ylabel('Price',size=12)
plt.legend()
plt.xlim(df2.index[0],df2.index[-1])
plt.grid()
fig.autofmt_xdate()
plt.subplot2grid*4
plt.plot(df2.index,df2['close'],label='Close', color='blue')
plt.xlabel('Time', size=12)
plt.ylabel('Price',size=12)
plt.legend()
plt.xlim(df2.index[0],df2.index[-1])
plt.grid()
fig.autofmt_xdate()
plt.show()
あえて今回はコードのみに留めます^^
長々となりましたが、ぜひ上記のコードを参考にしてみてくださいね。
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。
ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思いますし
デザイナーやWEBデベロッパー用などのコースも幅広くあるようなので
興味があるコースをチラ見してはいかがでしょうか^^
もちろん、個人で勉強する事もできますが、挫折経験のある私の個人的な経験から
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
それでは最後までよんで頂きありがとうございました!
plt.plot(df2.index,df2['volume'],label='Vol', color='green')
plt.xlabel('Time', size=12)
plt.ylabel('Qty',size=12)
plt.legend()
plt.xlim(df2.index[0],df2.index[-1])
plt.title('Futures Prices',size=18)
plt.grid()
Matplotlibの使い方をみてみよう!⑥
こんにちは!EMです^^
あけましておめでとうございます!!
2021年になりました。早いですね!
数年ぶりに大晦日に天ぷらそばを食べて年を越しました。
私が住んでいるカナダの地域では1月いっぱいまでロックダウンしていて
なかなか思う様に行動出来ない事もありますが
出来る事を愚直に2021年も行動の年にしていきたいと思うので
どうぞよろしくお願い致します。
という事で本題にいきましょう!
前回はMatplotlibの応用編について少しふれましたね。
Matplotlibについて飽きている人もいるかもしれませんが(笑)
ここではさらにどんな事が出来るのか見ていきたいと思います。
もし前回のグラフが分からない方は、一度戻ってみて頂きたいんですが
グラフの両端に余白があって、線がぷつっと切れているのが見えると思います。
これを修正するには、plt.xlim()コマンドを使用して
グラフ化する範囲をMatplotlibに正確に指示する事が出来ます。
前回のデータを使用し、0から49までグラフ化するように指示していきましょう。
fig = plt.figure()
plt.plot(df1.index,df1['A'],label='Stock A', color='red')
plt.plot(df1.index,df1['B'],label='Stock B', color='green')
plt.plot(df1.index,df1['C'],label='Stock C', color='blue')
plt.xlabel('Days After First Trade', size=10)
plt.ylabel('Price',size=12)
plt.legend()
plt.title('Stock Prices',size=18)
plt.grid()
plt.xlim(0,49)
plt.show()
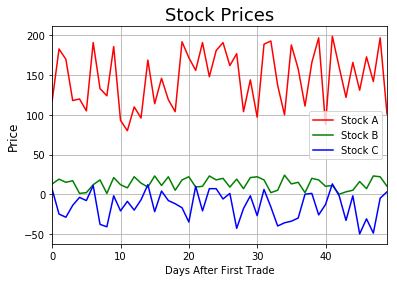
基本的に、グラフ化するときはx = 0に沿ってx軸に分かりやすくラベルを付けるのが好まれます。
これを行うには、x値がdf1.indexで、y値が
0*df1.indexである黒い線をプロットするようにMatplotlibに指示してみましょう。fig = plt.figure()
plt.plot(df1.index,df1['A'],label='Stock A', color='red')
plt.plot(df1.index,df1['B'],label='Stock B', color='green')
plt.plot(df1.index,df1['C'],label='Stock C', color='blue')
plt.plot(df1.index,0*df1.index,color='black')
plt.xlabel('Days After First Trade', size=10)
plt.ylabel('Price',size=12)
plt.legend()
plt.title('Stock Prices',size=18)
plt.grid()
plt.xlim(0,49)
plt.show()

さらに、グラフの線もスタイリッシュに操ることが出来ます。
y軸とラベルの間の追加の引数として、線の種類を指定していきましょう。
4つの選択肢として、それぞれ実線、破線、破線と点線、および点線が
'-','--','-
.',':'にてあらわす事ができます。 各df1列の線種と線幅の両方を変更してみましょう。
じゃーーーん!!
Matplotlibを使うとこの様なバリエーションも増えるという事を
感じてもらえたでしょうか?
ぜひグラフを作る際の参考になればと思います^^
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。
ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思いますし
デザイナーやWEBデベロッパー用などのコースも幅広くあるようなので
興味があるコースをチラ見してはいかがでしょうか^^
もちろん、個人で勉強する事もできますが、挫折経験のある私の個人的な経験から
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
それでは今日はここまでです!
最後まで読んで頂きありがとうございました!!
Matplotlibの使い方をみてみよう!⑤
こんにちは!EMです^^
今年もあと少しですね。
2020年はみなさんにとってどんな年だったでしょうか?
私は自分がワクワクする事はなんなのかを見つけたり
機械学習をまなぼうと一歩を踏み出した好奇心の年だったかなと思います。
2021年はもっと活動的になれる行動の年にしたいですね。
という事で本題に入りたいと思います!
今回はMatplotlibのさらに応用編を見ていきたいと思っています。
2種類のデータフレーム(個別のインデックス)があるとしましょう。
もしシーケンシャルプロット( sequential plots)を使う場合は
次のようになります。
df = pd.DataFrame({'X':np.random.randint(0,100,30)},
index=pd.date_range('2016-01-01',periods=30,freq='h'))
df1['A'].plot(color='blue')
df.plot(color='green')


さらに応用編プロット
これまで見てきたプロット方法は、データセットをすばやく洞察するのに非常に便利ですが
Matplotlibを使用すると、グラフをより細かくカスタマイズする事が出来ます。
コードはもう少し複雑になますが、ざっと見てみましょう!
fig = plt.figure() # 変数の名前にfigureを宣言する
plt.plot(x, y1, label='name1', color='colorname or hex code')
plt.plot(x, y2, label='name2', color='colorname or hex code') # プロットしたい数だけ繰り返す
plt.xlabel('label for x', size=number)
plt.ylabel('label for y', size=number)
plt.legend()
plt.grid() # もしこれが含まれる場合、グリッドがグラフ内に配置されます。
plt.title('Title')
plt.show()
データフレームd1を使用してプロットを作成しましょう。
y軸を「価格」、x軸を「最初の取引後の日数」というラベルを付け
プロットのタイトルを「株価」にします。
グリッドをTrueに設定して、グラフにグリッドを表示します。
fig = plt.figure()
plt.plot(df1.index,df1['A'],label='Stock A', color='red')
plt.plot(df1.index,df1['B'],label='Stock B', color='green')
plt.plot(df1.index,df1['C'],label='Stock C', color='blue')
plt.xlabel('Days After First Trade', size=10)
plt.ylabel('Price',size=12)
plt.legend()
plt.title('Stock Prices',size=18)
plt.grid(b=True)
plt.show()

tadaaaaaaaaaaaaaa!!!!
より複雑な表をつくる事が出来ました!
細かい設定ができると表も一気に見やすくなりますね。
ちなみに皆様に朗報です!
私今まで知らなかったんですが、CodeCampさんが無料で5回分無料レッスンを
されているらしいです、、、!
私が他のオンラインスクールで機械学習のコースを受講した際は
グループレッスンで約2倍のお値段を払ったので
完全マンツーマンでこのお値段は超良心的だなと思います。。。
ぜひ気になる方は無料体験もされてるみたいなので、一度WEBサイトを見てみてくださいね。
データ分析は時代が変化しても、必ず重宝される分野だと思いますし
デザイナーやWEBデベロッパー用などのコースも幅広くあるようなので
興味があるコースをチラ見してはいかがでしょうか^^
もちろん、個人で勉強する事もできますが、挫折経験のある私の個人的な経験から
プロから基礎を学ぶのは、本当に超効率的な自己投資だと思います。
それでは続きはまた次回にしたいと思います^^
最後まで読んで頂きありがとうございました。